Redmon, J. and Farhadi, A., 2017. YOLO9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7263-7271).
Why I choose this paper?
The first generation of YOLO network has one major disadvantage: low accuracy though it is fast. YOLOv2 made some changes to its predecessor, contributing to a far better trade-off between accuracy and speed. I may further understand what factors contribute to the promotion in speed and accuracy. But I will not cover YOLO9000 in this paper because the model is about weakly supervised learning, which I don't need to study now.
Abstract
We introduce YOLO9000, a state-of-the-art, real-time object detection system that can detect over 9000 object categories. First we propose various improvements to the YOLO detection method, both novel and drawn from prior work. The improved model, YOLOv2, is state-of-the-art on standard detection tasks like PASCAL VOC and COCO. Using a novel, multi-scale training method the same YOLOv2 model can run at varying sizes, offering an easy tradeoff between speed and accuracy. At 67 FPS, YOLOv2 gets 76.8 mAP on VOC 2007. At 40 FPS, YOLOv2 gets 78.6 mAP, outperforming state-of-the-art methods like Faster R-CNN with ResNet and SSD while still running significantly faster. Finally we propose a method to jointly train on object detection and classification. Using this method we train YOLO9000 simultaneously on the COCO detection dataset and the ImageNet classification dataset. Our joint training allows YOLO9000 to predict detections for object classes that don't have labelled detection data. We validate our approach on the ImageNet detection task. YOLO9000 gets 19.7 mAP on the ImageNet detection validation set despite only having detection data for 44 of the 200 classes. On the 156 classes not in COCO, YOLO9000 gets 16.0 mAP. YOLO9000 predicts detections for more than 9000 different object categories, all in real-time.
Aim
Error analysis demonstrates two significant shortcomings of YOLO:
- High localisation errors compared to Fast R-CNN.
- Low recall compared to region proposal-based methods (Faster R-CNN).
Therefore, this paper aims to improve recall and localisation while maintaining the classification accuracy.
Summary
The main contributions that this paper made in the improved YOLOv2 are:
- Improved the resolution of training images.
- Applied anchor boxes (from Faster R-CNN) to predict bounding boxes.
- Replaced the fully connected layer in the output layer in YOLO with a convolutional layer.
Another contribution is that they used a new dataset combination method and joint training algorithm to train a model on more than 9000 classes.
Better
In details, these contributions that makes it more accurate are as follows.
Batch Normalization. This brings improvements in convergence and helps regularize the model. Thus, the dropout is removed with no worry about overfitting. This change leads to more than 2% improvement in mAP.
High Resolution Classifier. Unlike other SOTA detection methods including YOLO, YOLOv2 trains the classification network at $448\times 448$ resolution for 10 epochs on ImageNet and then tunes it on detection. This change leads to about 4% increase in mAP.
Anchor Boxes. The previous version YOLO used fully connected layers to predict the locations of bounding boxes. YOLOv2 makes use of an important method proposed in Faster R-CNN called the anchor box. Before training, we have pre-set a group of multi-scale and multi-localised fixed boxes. For each anchor box, the model predicts the class and the IoU of the ground truth and the proposed box. Every box is responsible for the detection of the objects with the IoU value greater than the threshold. Then the convolutional layers predict the offsets of the boxes to the ground-truth boxes at every location in a feature map ($13\times 13$).
Several changes are made to implement the anchor boxes.
- Removed the fully connected layers from YOLO and used anchor boxes.
- Deleted one pooling layer to increase the resolution of the convolutional layers' output.
- Adjust the input images to the network from $448\times 448$ to $416\times 416$.
Therefore, YOLOv2 would have a feature map with odd numbers of rows and columns. The downsampling factor is 32 then the feature map is of size: $416/32\times 416/32$, i.e. $13\times 13$. This is good for the objects that are especially large because they often occupy the center of the image.
YOLOv2 benefited a lot from the anchor boxes. Despite the slight decrease in the accuracy, YOLOv2 witnessed an rise by 7% in recall from 81% to 88%. This is because YOLOv2 can predict over 1000 bounding boxes per image, much higher then 98 boxes predicted by YOLO.
However, using anchor boxes, the authors encounter two issues. Handling the two issues brings a rise of 5% in mAP.
Hand-picked box dimensions. The previous method used in Faster R-CNN requires us to manually choose the prior boxes. The new method in YOLOv2 proposed a k-means clustering on the training set bounding boxes to generate better priors without human intervention. Since the Euclidean distance leads to larger error in larger boxes, the authors modified the distance metric and made it associated with IoU to get higher IoU scores: $d(box,centroid)=1-IOU(box,centroid)$. Comparisons show that Cluster IoU implements a better representation of the bounding boxes and k=5 is the best trade-off.
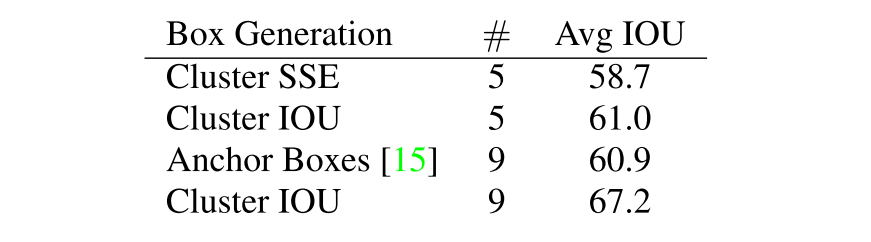
Model instability. The rule of RPN struggles to predict stable and sensible offsets. Therefore, the authors follow the idea of YOLO, predicting the boxes' locations relative to those of the grid cells. The results are constrained between ==0 and 1==.
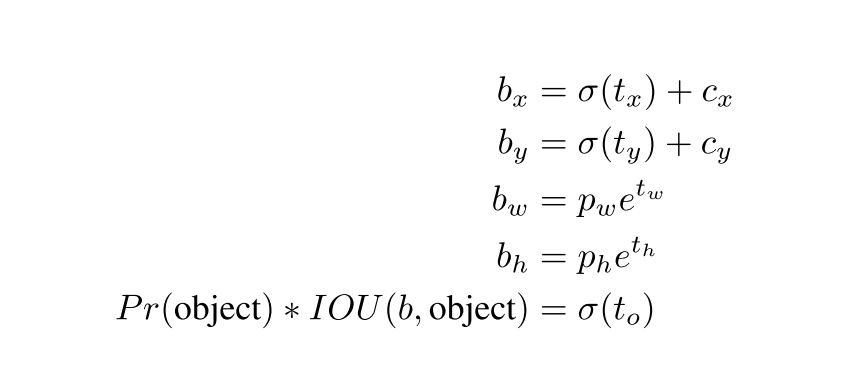
Fined-Grained Features. They proposed this to improve the localisation of small objects. Faster R-CNN and SSD algorithms both applied various feature maps to fit in different scaled objects. But YOLOv2 simply added a passthrough layer, which stacks adjacent features into different channels, resulting in the higher resolution features. This method changes the $26\times 26\times 512$ feature map into a $13\times 13 \times 2048$ one, contributing to a 1% increase.
Multi-Scale Training. This is exactly the improvement that makes YOLOv2 easily trade off between accuracy and speed, outperforming YOLO. The model automatically changes the new image dimensions to the value among the multiples of 32, from 320 to 608, every 10 batches.

Faster
To make to algorithm even faster, the authors also proposed a new classification model. Most detection base is VGG-16, which is accurate but extremely computationally expensive. YOLO is based on GoogleNel, fast enough but not very accurate. Then, the new base if Darknet-19, which is similarly accurate as VGG-16, but requires only about 1/5 operations.
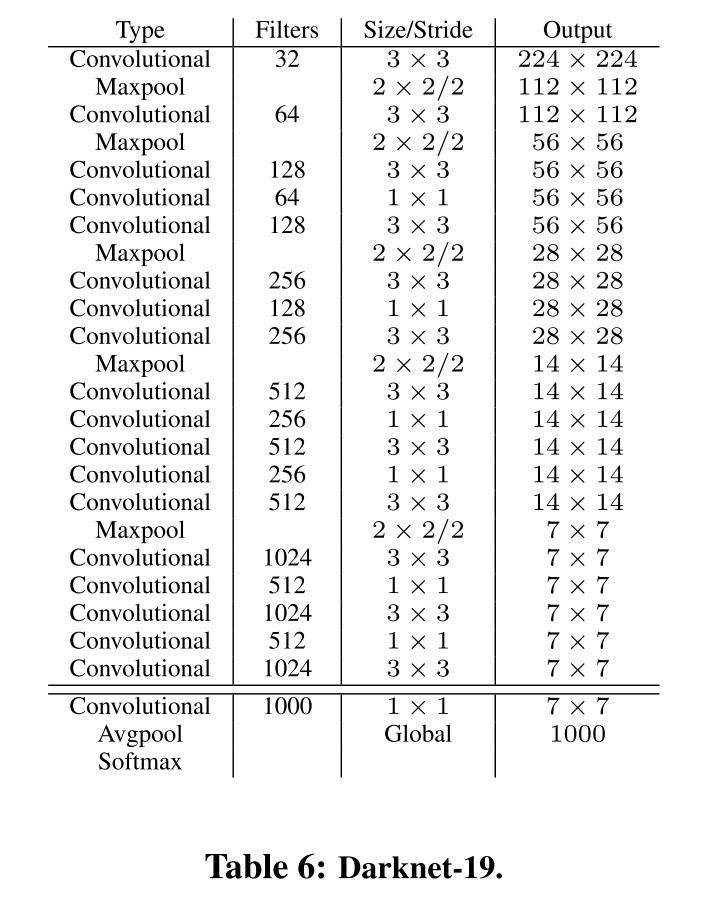
Experiment on training for classification. They trained the network on the standard ImageNet 100 class classification dataset. The network achieves a top-1 accuracy of 76.5% and a top-5 accuracy of 93.3%.
While training for detection, they need to modify the network to make it suit the dataset.
Further experiments
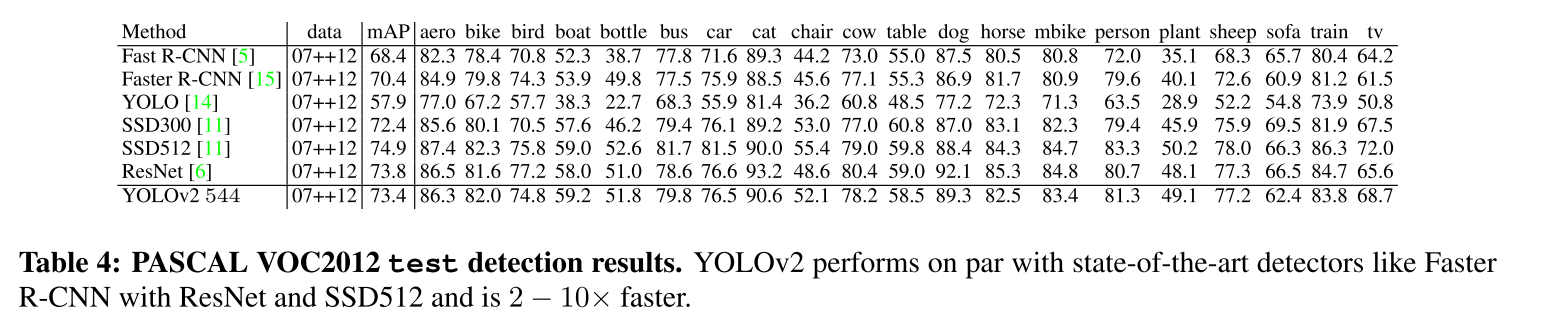
are conducted on VOC2012 and COCO. On VOC2012, YOLOv2 achieves 73.4 mAP while still running much faster ($2-10\times$) than other methods. On COCO, YOLOv2 achieves 21.6 mAP, not on the top but still competitive.
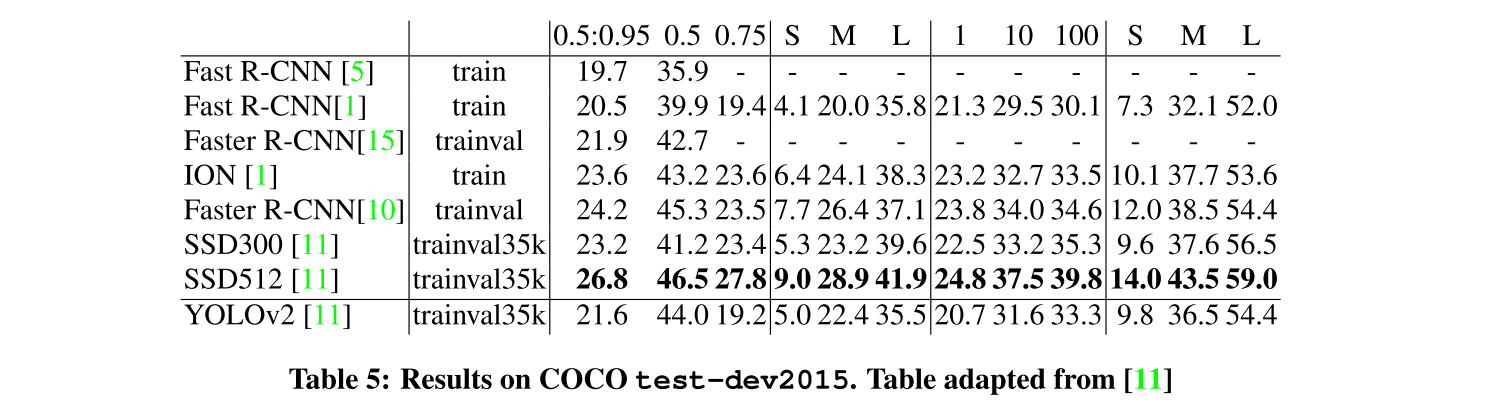
Comments
My thoughts
I think this is an excellent paper. It detailly described how the previous version was improved step by step, which is quite impressive. But I may argue that there is some vagueness in the paper, such as there is no statement about the threshold of deciding recall.
Comparison
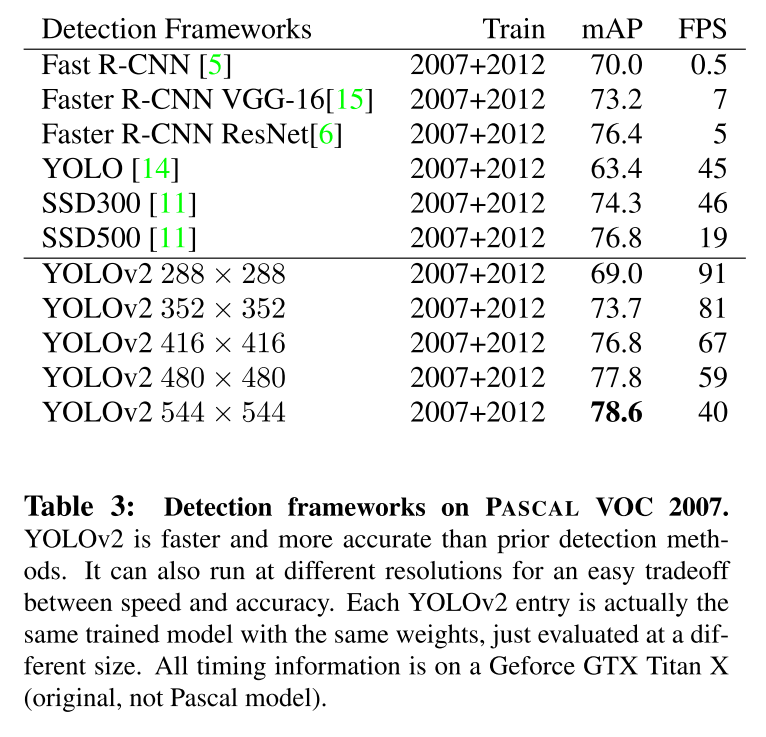
Compared to the predecessor YOLO, YOLOv2 contributes to sharp increase by 15% in mAP of the training on VOC dataset. And the anchor box method accounts for the most percentage at 5%, which proves the exceptional competence of anchors boxes in predicting bounding boxes.
Compared to the previous state-of-the-art algorithms: Faster R-CNN and SSD, YOLOv2 outperforms them, based on the analysis on VOC datasets. It can achieve 78.6 mAP at 40 FPS, bother higher than those of other algorithms.
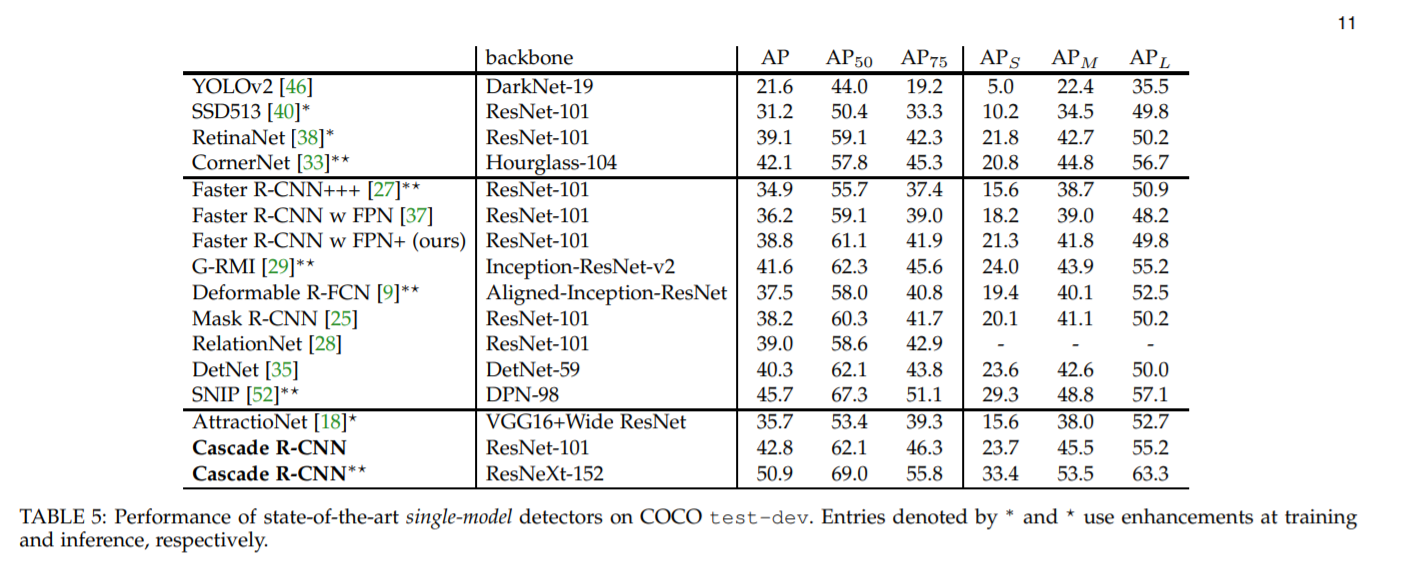
However, I briefly checked the newest SOTA algorithm by July 2019; the most powerful algorithm is called Cascade R-CNN, which achieves 50.9 mAP on COCO test-dev while that value for YOLOv2 is only 21.6.
Applications
There are two main applications of YOLOv2.
- At low resolutions. YOLOv2 is a low-cost but accurate detector. It achieves good accuracy at 90 FPS, quite suitable for smaller GPUs, high framerate video or streaming.
- At high resolutions, YOLOv2 is a state-of-the-art detector at high FPS. However, it is still not the best due to its uncompetitive results on more challenging benchmarks like COCO dataset.