本文将总结目标检测中的重要经典R-CNN family算法,包含R-CNN,Fast R-CNN,Faster R-CNN以及Mask R-CNN。
R-CNN
R-CNN (Girshick et al., 2014)意为Regions with CNN features或者说Region-based CNNs,说明CNN是对region操作的。R-CNN是第一个将深度学习的CNN运用到目标检测中的,在之前虽然CNN(如AlexNet)已被运用到图像任务中,但一般是图像的分类,通过穷举窗口运用传统的SIFT,HoG算法来提取特征然后进行分类,最后采用NMS缩小范围。R-CNN还遵循着传统目标检测的思路,首先使用selective search识别出定量的候选区域,再采用CNN来选择提取候选区域的特征用于分类。R-CNN的亮点如下:
- CNN用于候选区域的特征提取;
- 当拥有训练标签的训练数据不足时,采用预训练(Pre-train)已知CNN模型以及精细化(Fine-tuning)。
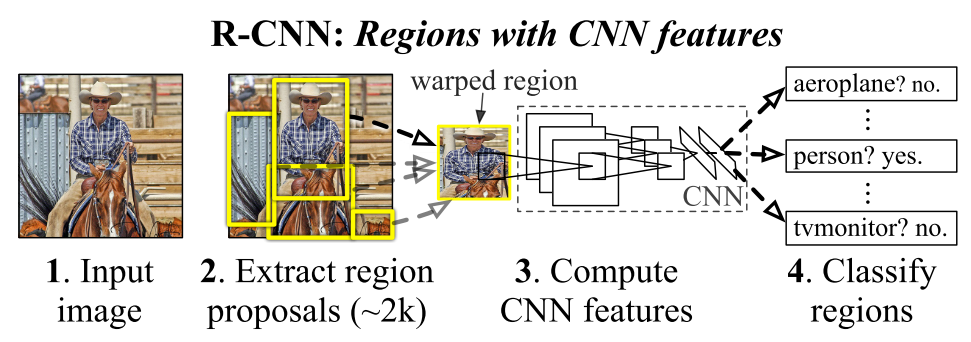 ◎ Object detection system overview. Credit: Girshick et al., 2014
◎ Object detection system overview. Credit: Girshick et al., 2014模型原理
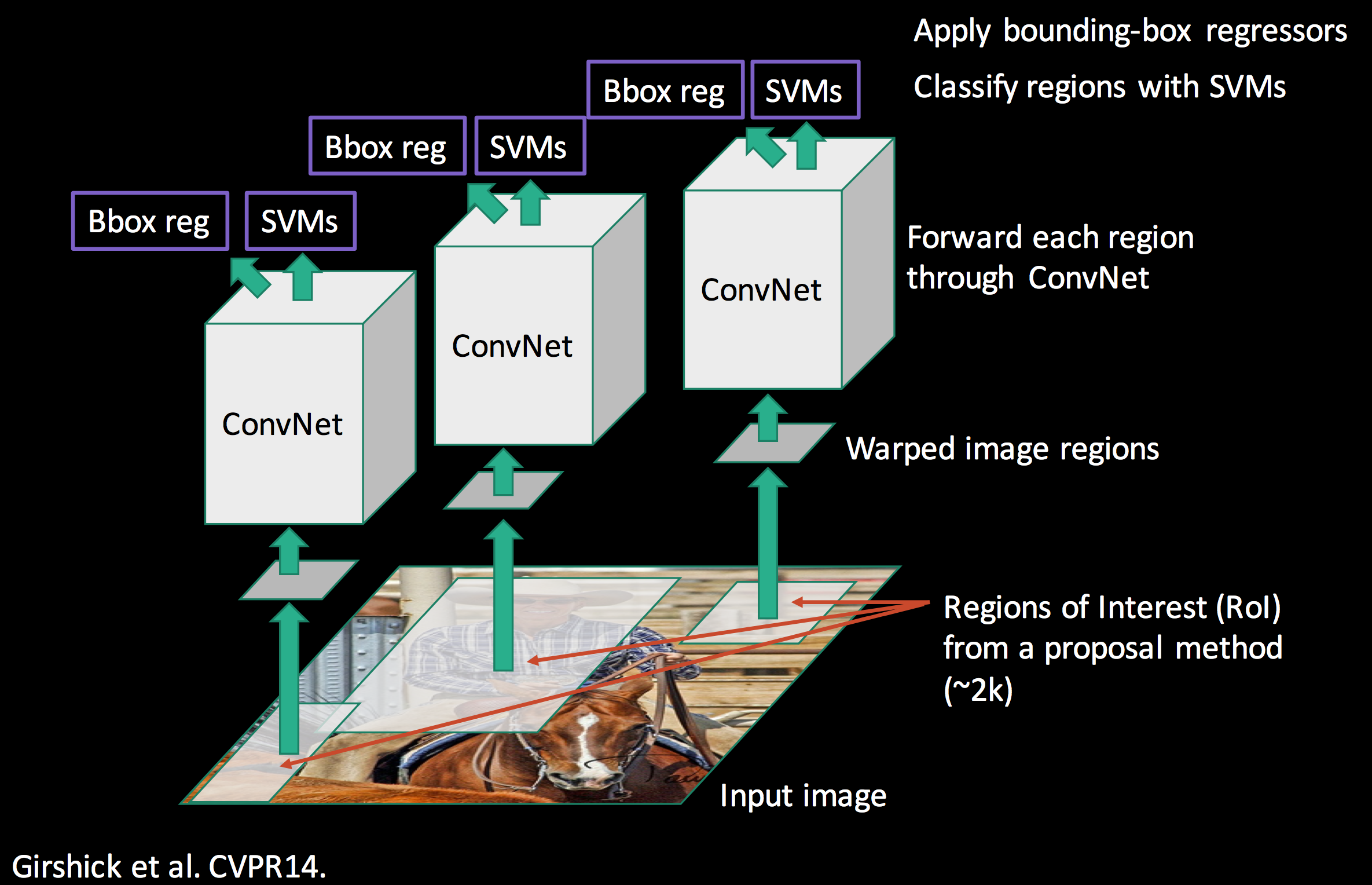 ◎ Credit: Analytics Vidhya
◎ Credit: Analytics VidhyaR-CNN分为三部分:1. 产生区域候选;2.提取区域特征;3.线性SVM分类。基本结构在上图就可以明显体现出来,那么R-CNN是怎么工作的呢?
在图像分类任务上预训练一个CNN网络,如在ImageNet上训练的VGG, ResNet。分类任务包含N个类别。
使用selective search得到区域候选(每张图片2k区域候选)。候选区域大小各异,可能会包含目标。
把候选区域变形(warp)为正方形(227×227),喂给CNN。
R-CNN一个慢的原因就是只喂候选区域,我要是继续选择用这种方法去做识别分类有点慢了,不过可以拿来讨论。

微调(Fine-tune)CNN网络,使之适合在K+1个类别的任务上运行。多的这个
1是指什么目标都没有的background。这一阶段使用很小的学习速率,每一个批数据也会经历一次困难样本挖掘,增加正样本的数量,这是由于候选区域大多数都是背景。对于每个区域,由CNN产生一个“特征向量”(4096维)。这个特征向量对于每一类都独立地输入给二分类SVM。对于二分类SVM,当候选区域与ground-truth的$\text{IoU}\geq 0.3$时,该区域看作正样本,反之则为负样本。
为了提高定位精度,训练预测边界框的4个校正偏差的Bbox回归模型。
边界框回归
边界框回归是为了更准确地预测编辑框和真实框之间的矫正关系的转换。对于一个预测框$\vec{p}=(p_x,p_y,p_w,p_h)$ (中心坐标和宽度,高度),以及它对应的真实框$\vec{g}=(g_x,g_y,g_w,g_h)$,矫正关系的转换包括边框中心坐标的尺度转换以及边框尺寸之间的对数转换,这些转换以$\vec{p}$为输入,输出校正参数。
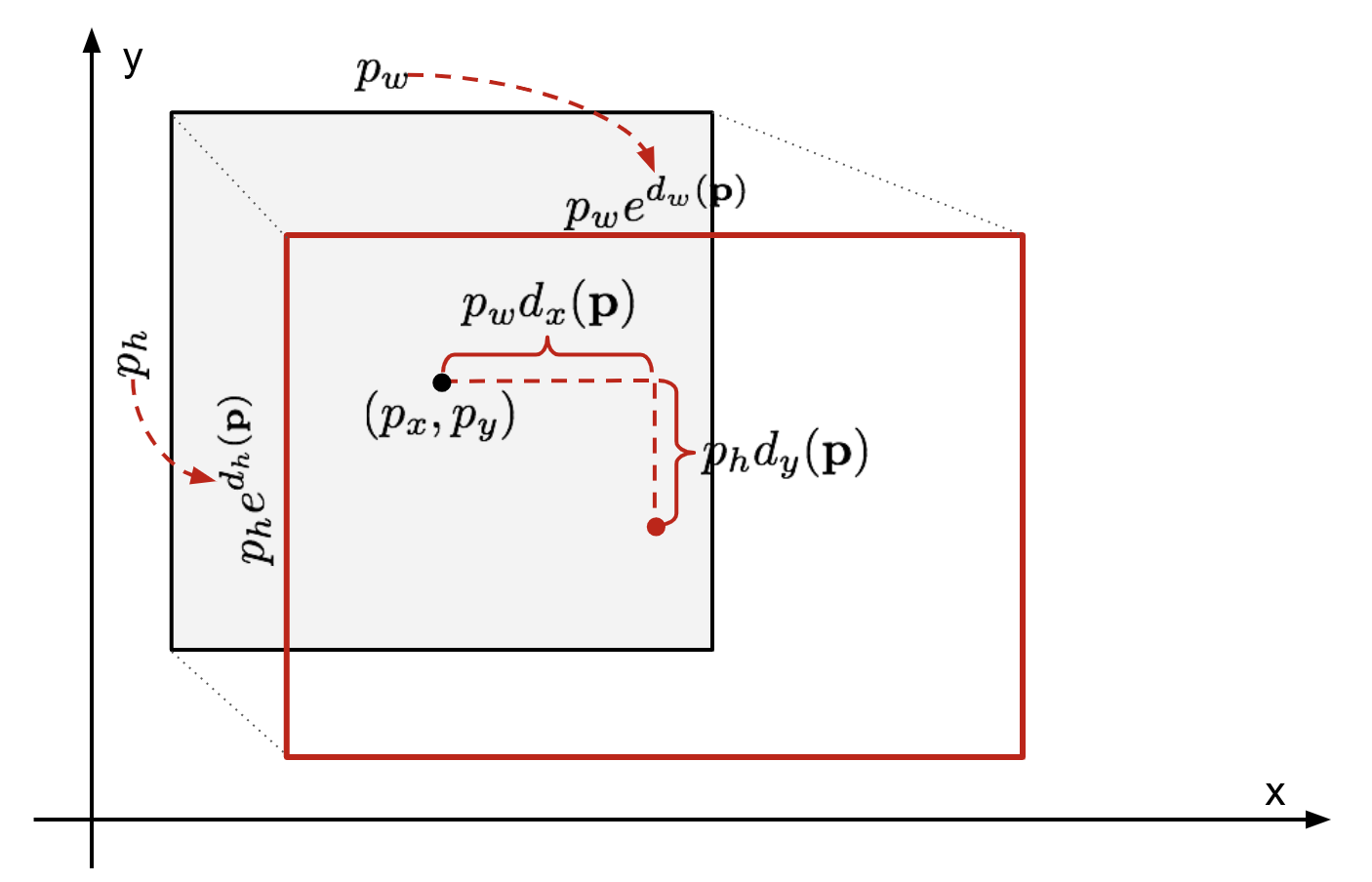 ◎ 预测框与真实框转换 Credit: References-1
◎ 预测框与真实框转换 Credit: References-1对应上图的转换关系为:
$$
\begin{aligned}
\hat{g}_x&=p_wd_x(\vec{p})+p_x \\
\hat{g}_y&=p_wd_y(\vec{p})+p_y \\
\hat{g}_w&=p_w\text{exp}(d_w(\vec{p}))\\
\hat{g}_h&=p_h\text{exp}(d_h(\vec{p}))
\end{aligned}
$$
YOLOv3的锚框方法中,中心坐标的转换关系用$\sigma$函数替代了,因为YOLOv3是以特征图提出候选的,只需要0-1之间的坐标偏移。
边界框变换函数$d_i(\vec{p})$可以接受任何的,不局限于0-1的输入,所以对网络输出也没有特别要求。根据变换关系反推,边界框回归所要学习的矫正参数:
$$
\begin{aligned}
t_x&=\frac{g_x-p_x}{p_w}\\
t_y&=\frac{g_y-p_y}{p_h}\\
t_w&=\text{log}(\frac{g_w}{p_w})\\
t_h&=\text{log}(\frac{g_h}{p_h})
\end{aligned}
$$
对于代价函数,可以选择SSE (Sum Squarred Error),如果包含规范化:
$$
L_{\text{reg}}=\sum_{i\in{x,y,w,h}}(t_i-d_i(\vec{p}))+\lambda|\vec{w}|^2
$$
暂时对于变换函数还不是特别明白,希望看了对应代码之后能更了解。
细节
正负样本定义
在微调和SVM训练中,都使用到了“正/负样本”的概念,但是在两种情况下概念含义是不同的。在微调中,为了保证CNN网络能处理足够数量的含目标的候选框,正样本定义为“包含目标的候选区域”;而在SVM训练中,正样本则被定义为IoU高于一定阈值的边界框。
优势技巧
共享的CNN。即同一套CNN参数用于所有类别的检测。
低维的特征向量。CNN对每一个候选区域只产生4096维的向量,远低于当年其他常见方法。