探索大多数前人忽略的detection(人脸)和alignment(人脸关键点)的潜在关系,结合起来就可以同时进行两项任务,加速算法。
三级的卷积神经网络级联架构,从粗到精策略预测
脸部face和关键点landmark位置,设计了可实时的轻量级CNN;Multi-scale通过输入的image pyramid实现,不同于Faster R-CNN衍生的anchor box-based的算法。
提出新的online hard sample mining strategy(传统offline),在实践中效果更好。
在FDDB,AFLW和WIDER FACE benchmarks上SOTA,在自标注的数据集有实时效果。
README
这篇博客既包括对论文的总结(但是不包括实验和结果部分),也包括对代码的逐段研究。如果从前到后看可能不太习惯形成整体思路,建议参考目录,首先看没有“详述”和“代码”字眼的目标段落,因为按照由浅入深的顺序,应该先看论文提炼的精简介绍,再看代码是如何细分任务实现算法的。然后应该产生对论文的疑惑,建议接着看“3. 创新点和问题”,尽量看看自己是不是还有这些疑惑或者有新的理解。最后回到前面详述和代码解读的部分,看懂detection包括那些细节,问题时怎么解决的。
架构讲解
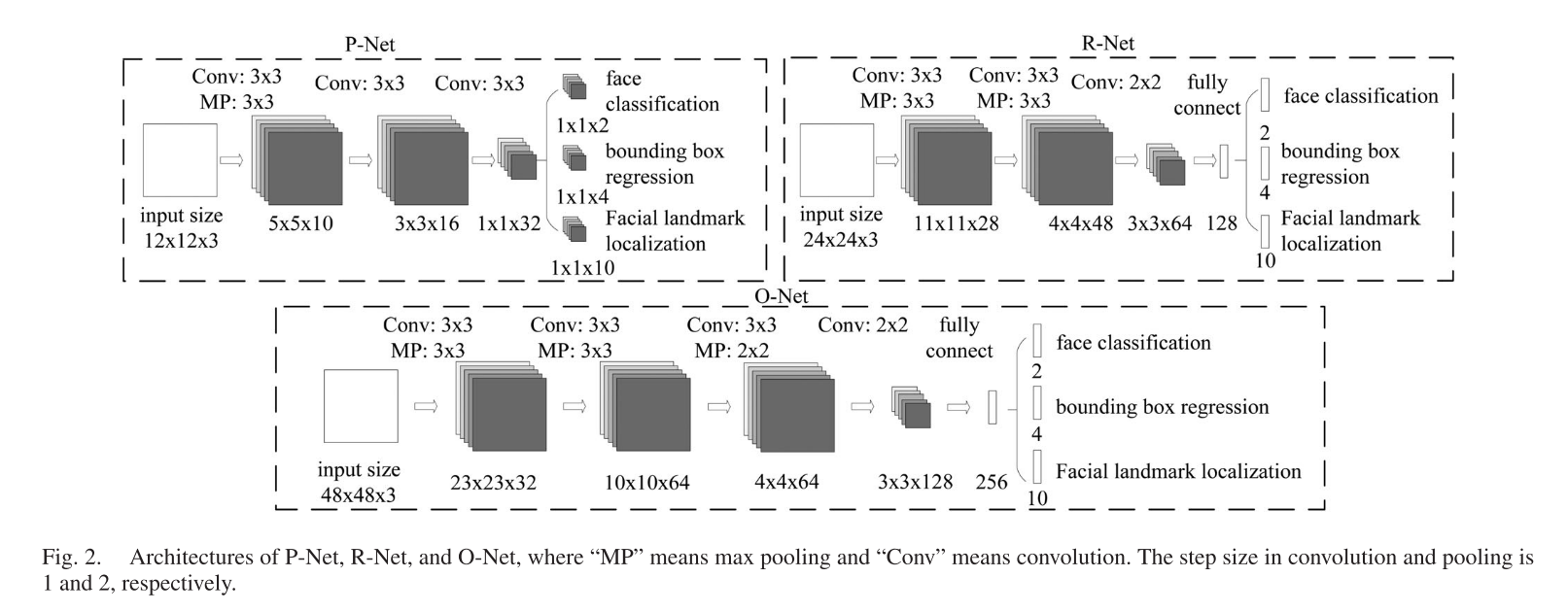 ◎ MTCNN网络结构图
◎ MTCNN网络结构图MTCNN包含级联的三个多任务卷积神经网络:Proposal Network (P-Net),Refine Network (R-Net),Output Network (O-Net)。每一个CNN都有三个学习任务:人脸分类,边框回归,关键点定位。
精简地说,三级CNN分别的作用为:
P-Net: Proposal Network,全卷积网络(FCN),可以接受任意大小的输入。获得脸部候选窗口和他们的bbox回归。脸部候选窗口通过bbox回归进行校正,最后采用NMS合并重叠候选框。
R-Net: Refine network滤掉非常多的非人脸候选框,再次使用bbox回归进行校正,使用NMS筛选。
O-Net: 和R-Net相似,但是对输入数据进行更进一步提取,最终还会输出五个脸部关键点。
图片准备
给定一张图片,将其多次resize得到图片金字塔,作为接下来级联架构的输入。初始缩放比例为resize_factor(具体根据数据集人脸大小分布确定,基本在0.7-0.8之间会比较合适),其后的缩放比例为${resizeFactor}^i$ (i=1, 2, 3...),直到最小的图片短边刚好大于或等于12,缩放停止。这些图像的大小就变成了${originalSize}\times {resizeFactor}^i$的金字塔,要一幅幅输入到P-Net中去。
另一种构造图片金字塔的方式是先规定一个最小的人脸尺寸$minFaceSize$,如15。那么所有的缩放图片的的缩放比例为$originalSize\times \frac{12}{minFaceSize}\times resizeFactor^i$。这样做的好处是:金字塔图片会变少。要是图片尺寸是小于人脸最小值规定值(如14),那么这样的图片就不会参与金字塔了,避免过多进算量。
 ◎ 金晨小姐姐,[1024*576]
◎ 金晨小姐姐,[1024*576]对于一张图片如图,采用第二种方式我们可以得到所有的缩放比例为:
| |
P-Net
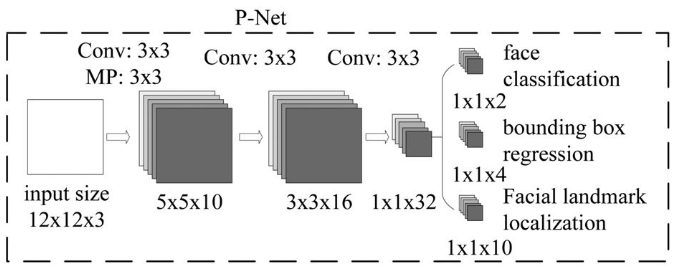
输入一张图片,得到脸部候选框和Bbox regresion vectors(IOU和位置信息),接着根据bbox vectors筛选(calibrate)更少的bbox,最后采用NMS再筛选。
前向传播过程详述
下面我把上图的过程详细叙述一遍然后补一张自己画的流程图,补充一下论文图没有体现出来的信息(在后面两个Net里我就简单叙述了)。注:卷积层的padding均为0。
输入:[12, 12, 3],在PyTorch为[1, 3, 12, 12]。
经过第一层卷积层(stride=1),10个3×3的卷积核(channel-height-width),输出10通道10×10图片;PReLU激活函数激活,注意这个implementation中的PReLU层使用的不是默认的单个a值,而是每一层(通道)都对应一个需要学习的a值,输出是不会改变图片维度的;经过3×3的最大池化层(stride=2),生成10通道5×5的特征图。可以拿PyTorch简单测试一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26class testNet(nn.Module): def __init__(self): super(testNet, self).__init__() self.conv1 = nn.Sequential( nn.Conv2d(3, 10, 3, 1), nn.PReLU(10) ) self.pool1 = nn.MaxPool2d(3, 2, ceil_mode=True) def forward(self, x): print('Input: ', x.size()) x = self.conv1(x) print('After conv2: ', x.size()) x = self.pool1(x) print('After MP: ', x.size()) if __name__ == "__main__": testnet = testNet() print(testnet) input_tensor = torch.rand((1, 3, 12, 12)) print(input_tensor) y = testnet(input_tensor) # Input: torch.Size([1, 3, 12, 12]) # After conv2: torch.Size([1, 10, 10, 10]) # After MP: torch.Size([1, 10, 5, 5])这张10通道5×5的特征图再次经过卷积核为16个3×3的filters的卷积层,由于padding为0,所以输出是16通道的3×3的特征图;同样地,PReLU层不改变维度。
经过有32个3×3的卷积核的卷积层,padding为0,所以输出为32层的1×1的特征图;同样的,PReLU层不改变维度。
最后一步,从一个1×1×32的特征图转化为三个特征图[1],分别是1×1×2(用于人脸分类任务,是和不是的二分类),1×1×4(用于边界框回归任务,分别对应左上角两个坐标,宽和高),1×1×10(用于脸部关键点定位任务,分别对应五个点是个坐标)。这些特征图都抽象了三个任务所要学习的图像特征,这些图像特征的具体表示可以见下一节的损失函数。
总结一下P-Net的流程图:
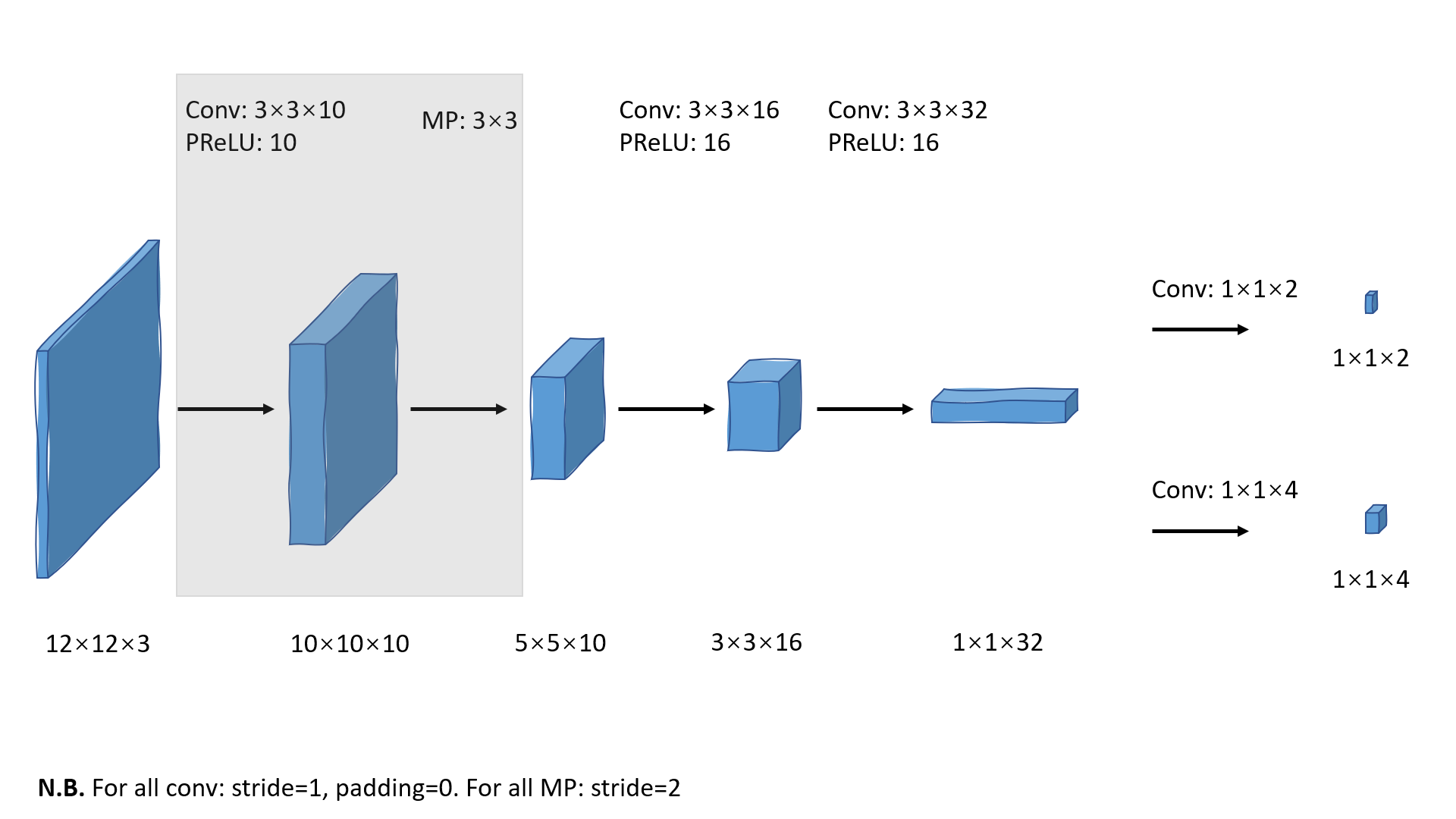 ◎ 使用PowerPoint画的P-Net流程图
◎ 使用PowerPoint画的P-Net流程图代码解读:一次inference
刚刚说的是一张图片生成特征图以及一个候选框信息的过程,我们怎么得到大量的候选呢?事实上,这里的[12, 12, 3]大小的图片是训练集图片,并不是实际检测任务中使用的大图片,如[1024, 576, 3]。大图片经过P-Net最终不会只剩[1, 1, m]这么小的特征图,而是更大二维尺寸的特征图(通道一样)。现在我们就用上面给出的金晨小姐姐的图片来解释某一次scale=0.8下的图片输入P-Net得到的输出。
网络前向传播部分:
- 输入大小为[1024, 576, 3]的图片和scale=0.8,将图片resize为[820, 461, 3]。当然,每一个scale都要进行一次前向传播,这里只谈一个scale下的情况;
- 将图片输入P-Net,得到的实际输出为分类特征图[405, 226, 2]和候选框特征图[405, 226, 4];
- 两个特征图的H(226)和W(405)一样,对应位置表示同一候选框,分类特征图对应两个通道分别表示此候选无脸和有脸的概率,候选框特征图四个通道分别表示此候选框和真实框偏移信息的预测。所以一共得到$226\times 405=91530$个候选。候选框的索引(坐标)反映候选框位置。
筛选部分:
利用分类分数初筛。只保留人脸概率大于一定阈值的候选框,保留下来的候选框只有59个;
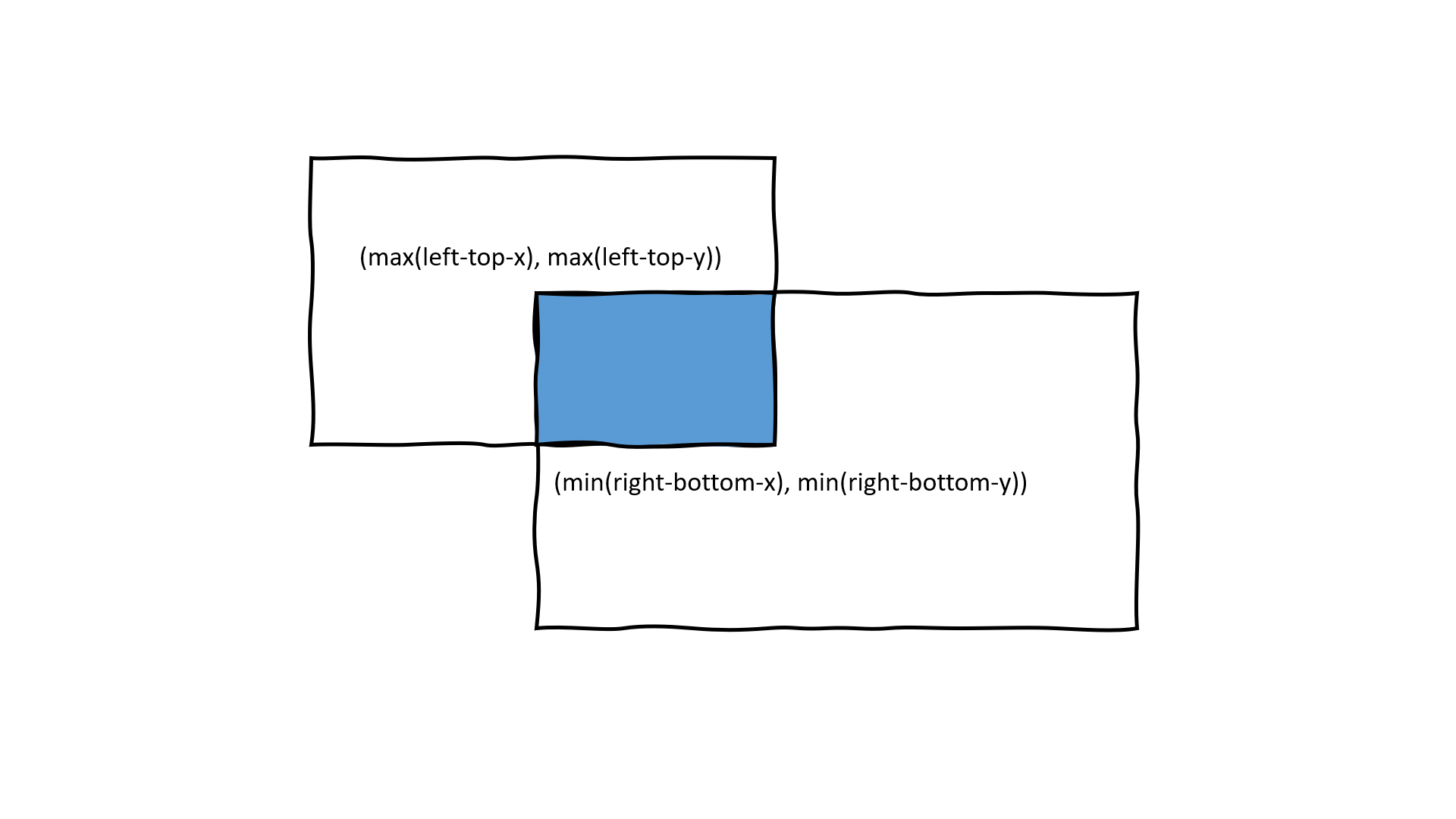
将剩下的候选框坐标映射到原始图片中,结合代码和文章分析,映射过程如图,首先应将点坐标乘stride=2,映射到缩放图中,然后右下角坐标加上12,最后映射到原图中。缩放得越小,特征图上的点对应原图中的感受野就越大。这一步结束后,所有的候选框都映射到原图中且有对应的score和offsets;
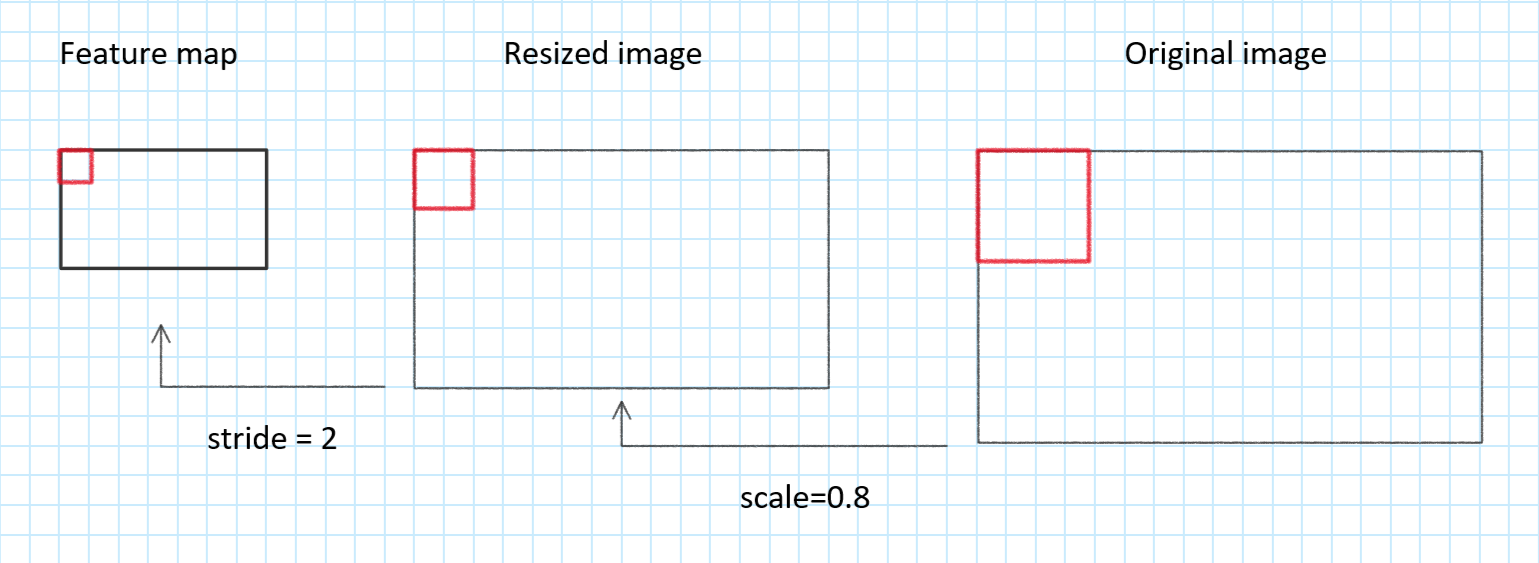 ◎ 映射过程
◎ 映射过程但是具体为什么说"applying P-Net is equivalent, in some sense, to moving 12x12 window with stride 2",我暂时真的不理解。
NMS,去掉重叠过多的框。首先找到分类分数最大的候选框,然后计算其他候选框与分数最高候选之间的IoU值(如图),舍弃掉其中IoU值大于0.5的候选框。这一步结束后scale=0.8情况下剩28个边界框,所有的scale都做完这一步还剩134个边界框;
 ◎ 计算交并比IoU
◎ 计算交并比IoU校正和裁剪。将P-Net预测的offsets加入位置信息进行校正,然后将边界框按照长边扩展成正方形边界框,以备下一级网络使用。
R-Net
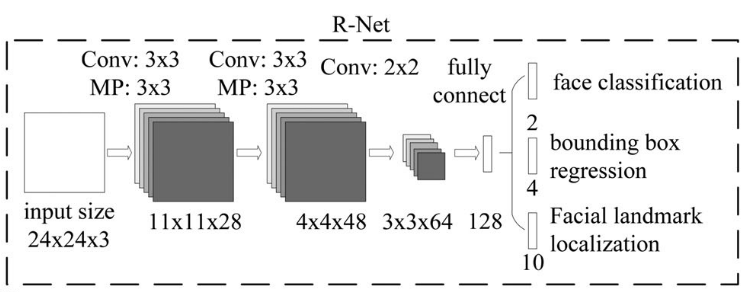
从[3, 3, 64]的特征图到128之间经过了flatten和全连接层。Flatten将三维的tensor压平成一列tensor,即类似[576, 1]的tensor。全连接层将列向量转化为含128个元素的列向量并且用PReLU非线性函数激活。最后一步仍然是分别产生用于三个任务的一维输出。完整过程见R-Net流程图:
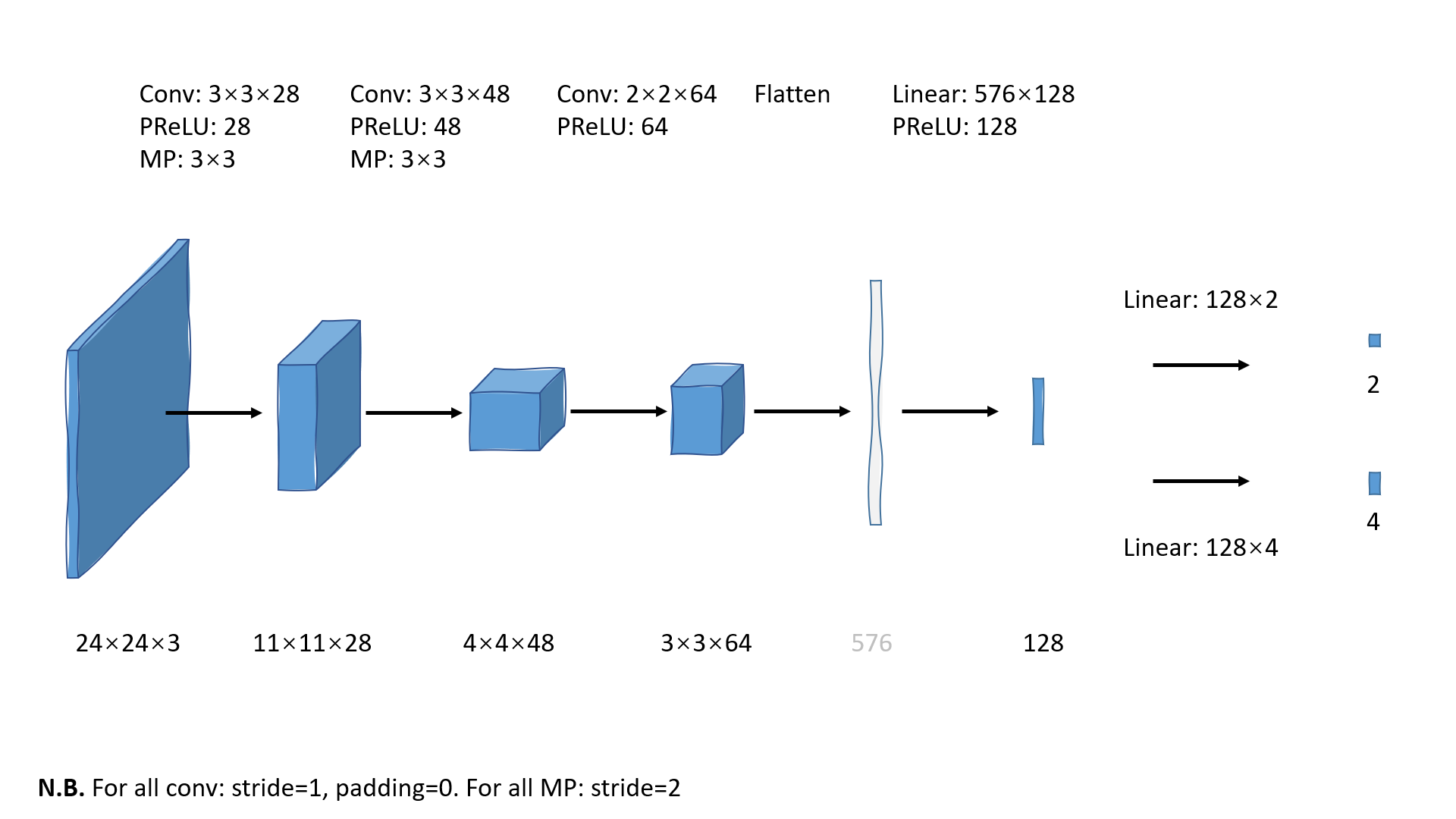 ◎ 使用PowerPoint画的R-Net流程图
◎ 使用PowerPoint画的R-Net流程图代码解读
将正方形的边界框以内的图片裁剪出来缩放为24×24的。这一步需要确定边界框所包围的区域都在图片内,不在的话就先constrain到图片范围,然后再缩放捕获区域到24×24。为便于理解,我把其中一个裁片imshow出来(采用permute函数快速处理tensor,无需先转numpy了):
1 2 3import matplotlib.pyplot as plt img_demo = img_boxes[0, :, :, :] plt.imshow(img_demo.permute(1, 2, 0)) ◎ 24×24边界框切片
◎ 24×24边界框切片将图片输入R-Net。我们从论文得知这一步的输出应该是两个二维的tensor:1×4和1×2,分别表示预测的偏移和分类分数。那么这一步输入多少图片裁片(如n)使得输出为[n, 4]和[n, 2]。这一步n=134。
分类分数筛选。按照比P-Net对应的初筛的阈值高一点的阈值,保留分类分数高的边界框。这一步结束边界框数量骤降到17个。
NMS再筛。按照同样的原理筛掉重叠过多的框。这一步结束还剩14个边界框。
校正和裁剪。把预测的offsets加入边界框位置信息,然后把它们转化为正方形。
O-Net
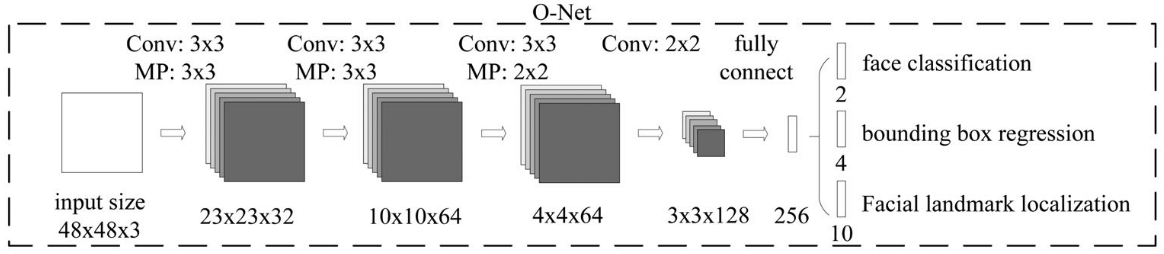
流程与R-Net类似,最后也是产生三个一维的tensor作为抽象的特征。O-Net流程图:
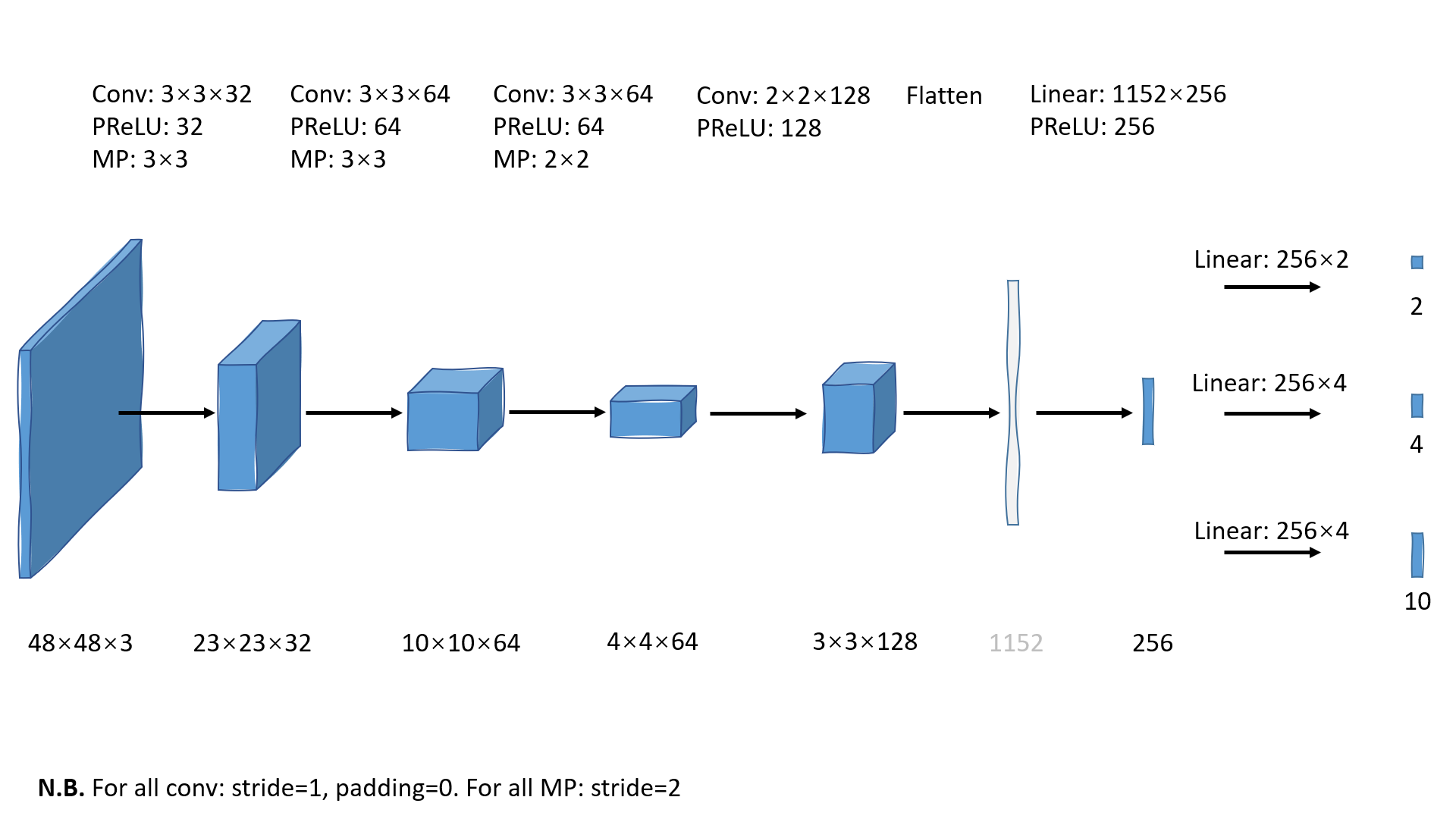 ◎ 使用PowerPoint画的O-Net流程图
◎ 使用PowerPoint画的O-Net流程图代码解读
调整输入为48×48大小。同R-Net阶段第一步差不多;[2]
 ◎ 48×48边界框切片
◎ 48×48边界框切片输入O-Net。这一步将会得到三个二维的tensor:[n, 10], [n, 4], [n, 2], n=14。它们分别表示边界框的landmarks位置信息,预测偏移和分类分数。
分类分数筛选。按照更高一点的阈值保留分类分数高的边界框。这一步结束还剩6个边界框。
NMS筛选。筛去与分数最高的边界框重叠过多的边界框,就只剩1个,检测过程到此结束。
把这一次检测过程用图表示出来为:
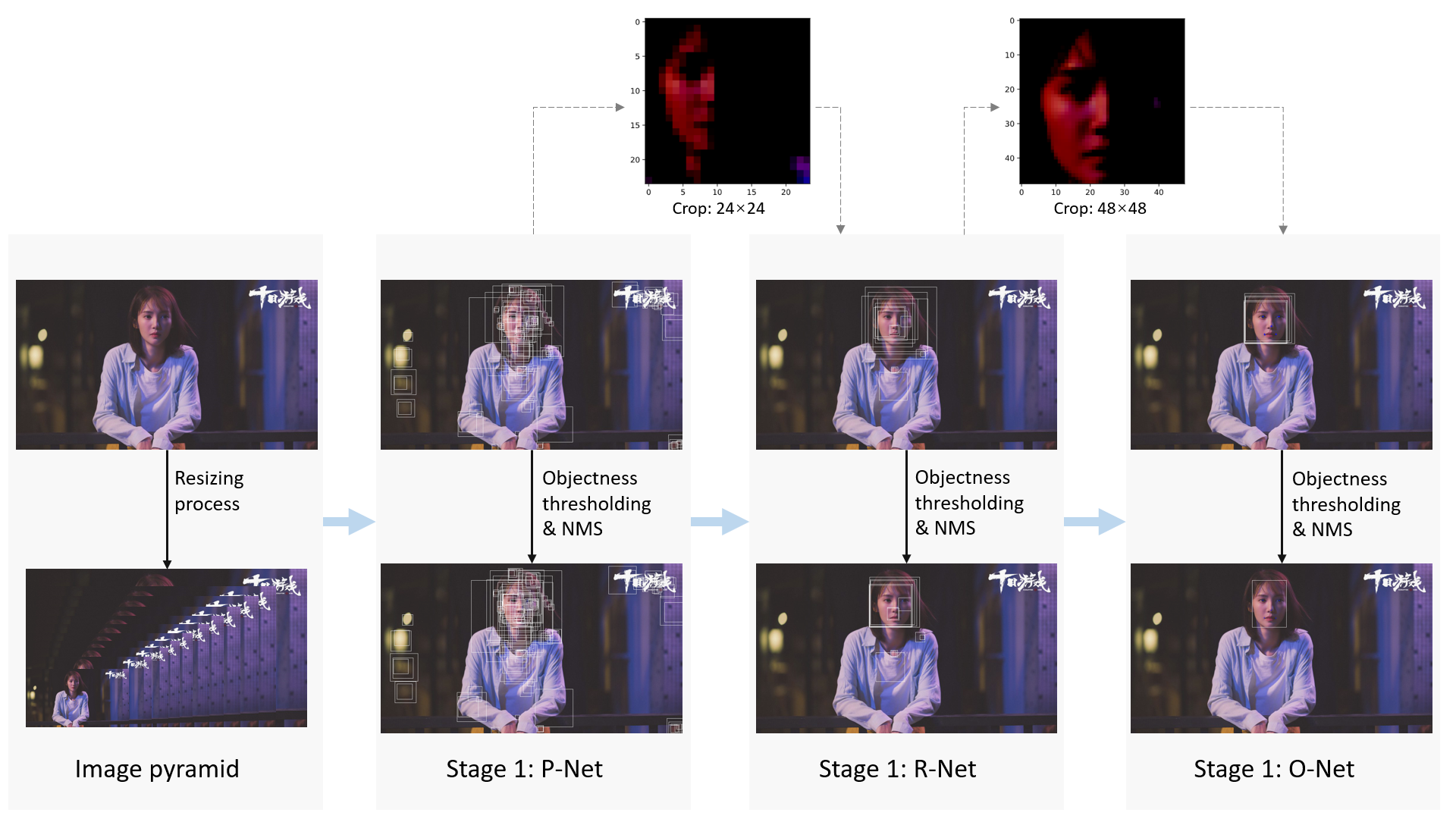 ◎ MTCNN做一张图片的人脸检测的过程
◎ MTCNN做一张图片的人脸检测的过程损失函数和训练
训练过程首先当然是一次前向传递的过程,每一级的CNN要完成三个任务:
- 人脸分类,Face/nonface classification,是二分类。
- 边界框回归,Bounding box regression。
- 脸部关键点定位,Facial landmark localization。
人脸分类
二分类问题,那么对于每一个sample $x_i$,论文采用常见的交叉熵(cross-entropy)损失函数: $$ L_{i}^{det}=-(y_i^{det}log(p_i)+(1-y_i^{det})(1-log(p_i))) $$
这里$p_i$是sample是人脸的概率,即网络输出的分类分数。$y_i^{det}\in{0, 1}$(注意是集合)表示真实标签。
边界框回归
对于每一个候选窗口,我们预测的是它和最近的真是bbox的偏离offset。学习的过程规定为回归问题,对于每个样本$x_i$采用欧几里得损失函数: $$ L_i^{box}=|\hat{y}_i^{box}-y_i^{box}|^2_2 $$
其中 $\hat{y}_i^{box}$ 是网络输出的回归框,$y_i^{box}$是标注的真实框,$y_i^{box}\in \mathbb{R}^4$ 。
论文说是left top, height, width,不过代码是$[x_{min},y_{min},x_{max},y_{max}]$,均是图片上的绝对值。
脸部关键点定位
和bbox回归类似,关键点检测也是一个回归问题,需要最小化欧几里得损失函数: $$ L_i^{landmark}=|\hat{y}_i^{landmark}-y_i^{landmark}|^2_2 $$ 戴帽子$\hat{}$的是网络输出的关键点坐标的回归值,不戴帽子的是真实值。$y_i^{landmark}\in \mathbb{R}^{10}$: left eye, right eye, node, left mouth corner, right mouth corner(代码是先存x值,再存y值,是相对于边界框的相对值,用0-1之间的比例表示)。
多源数据的训练
损失函数
考虑到照片很多样:有人脸,无人脸,部分人脸,以上三个损失函数并不是都要采用。比如没人脸的样本只需要计算人脸分类的损失函数$L_i^{det}$。那么一个综合的代价函数如下: $$ min\sum^N_{i=1}\sum_{j\in{\text{det,box,landmark}}}\alpha_j\beta_i^jL_i^j $$ 其中N为训练样本数量。$\beta_i^j\in{0,1}$是**样本类型指示变量**,表示有无人脸。$\alpha_j$表示**任务重要性**,0-1间取值,论文中使用的值为:
| Stage | $\alpha_{det}$ | $\alpha_{box}$ | $\alpha_{landmark}$ |
|---|---|---|---|
| P-Net | 1 | 0.5 | 0.5 |
| R-Net | 1 | 0.5 | 0.5 |
| O-Net | 1 | 0.5 | 1 |
训练数据
在训练中,论文将数据分为四种类型:
| 类型 | 定义 | 使用任务 |
|---|---|---|
| 负样本 | $IoU < 0.3$ | 人脸分类 |
| 正样本 | $IoU > 0.65$ | 人脸分类,边界框回归 |
| 部分脸 | $IoU\in[0.4,0.65] $ | 边界框回归 |
| Landmark脸 | 具有五个关键点的样本 | 脸部关键点定位 |
所有训练数据的分布为:3:1:1:2。
前面在P-Net中讲过,训练阶段的图片并不是我们使用的那么大的照片,而是每一级网络都有它们单独的训练集,图片尺寸分别是[12, 12, 3],[24, 24, 3]和[48, 48, 3]。三个网络单独训练,先训练好P-Net然后训练R-Net,最后训练O-Net。
在线难分样本挖掘
为了提升网络性能,需要进行hard sample mining。传统的方法是offline的,即在分类器训练好之后进行研究的。论文提出在训练过程中,对于人脸分类任务进行在线难分样本挖掘。实验说明这样做有更好的效果。
注:Girshick他们同样在2016年提出了OHEM,比MTCNN早四个月,但是我猜他们是分别提出来的,不过现在还没看论文,是不是一个原理再看。
Training Region-based Object Detectors with Online Hard Example Mining
深度学习难分样本挖掘(Hard Mining)- 知乎文章。
前向传播:在每个小批量数据里,对所有样本的损失进行排序,排名前70%的样本就是难分样本。
后向传播:只使用难分样本的梯度值(见反向传播算法-梯度)进行反向传播,忽略排名后30%的样本梯度,因为简单样本对加强检测器没有太大作用。
创新点和问题
和其他Multiple CNN比使用的filter有什么区别?
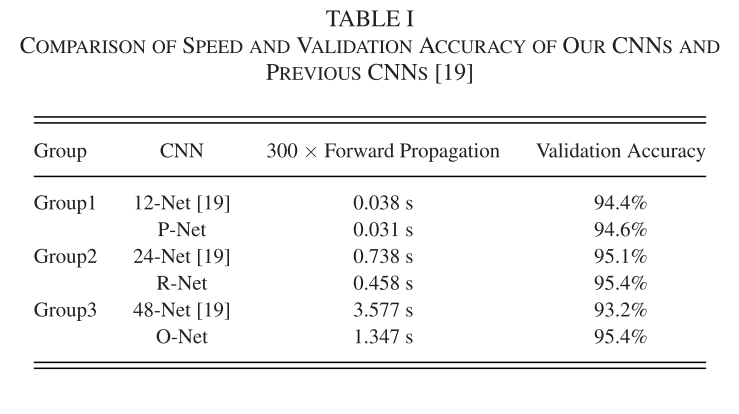
MTCNN为了简化计算,讲5-by-5 filter将为3-by-3 filter,但是增加了个数以增加输出深度,特征表现力更强。下图表现了这样做的速度和准确性提升。(在卷积层和全连接层后使用PReLu激活函数,除了O-Net)
和YOLO系列对比?
相似点是回归问题:MTCNN和YOLOv3在feature map的每一个格子都会预测边界框。YOLO系列也是将目标的边界框的定位当作回归问题做,通过减小锚框和真实边界框的损失函数,学习预测锚框缩放大小和偏移。不过不同点是,MTCNN在一个特征图格子只预测一个候选框,multi-scale通过图像金字塔实现,所以会有很多候选框;YOLOv3在一个特征图格子会预测三个候选框,multi-scale是通过三个拼接成的不同scale的特征图实现的,也会有很多候选框。
做个小测试吧:对于一张416×416的输入图片,MTCNN和YOLOv3相比,谁的最初候选框更多,分别是多少?注:图像金字塔生成方式: $$ originalSize\times \frac{12}{(minFaceSize=15)}\times (resizeFactor=0.7)^i $$
对于YOLOv3,特征图分别具有32/16/8的stride,那么特征图大小分别为13×13,26×26,52×52,每个格子预测3个边界框,总共: $$ (13\times 13+26\times 26+52\times 52)\times3=10647 $$
对于MTCNN,输入416×416,保证最小size是12,代码略,得到:
1 2 3 4 5scales: ['0.80', '0.56', '0.39', '0.27', '0.19', '0.13', '0.09', '0.07', '0.05', '0.03'] number of different scales: 10 rescaled image sizes: [333, 233, 163, 114, 80, 56, 39, 27, 19, 13] feature map sizes: [162, 112, 77, 52, 35, 23, 15, 9, 5, 2] number of candidates: 49510虽然候选数量都与图像大小有关,单MTCNN的候选数量与参数选择关系很大。
那么这样近乎五倍的关系,能说明YOLOv3比MTCNN又快又好吗?我也不太确定,暂时也不知道如何比较。不过现在似乎还算是anchor-based方法的天下,所以我暂时给出推测一个肯定的答案。希望以后能弄明白。
负样本和部分脸这两种数据为什么区间不对接?
因为这两类数据差异并不大,所以采用了IoU区间为[0.3, 0.4],符合人的思考方式(fuzzy theory)(我猜想),实践来说容易使模型收敛。
感觉可以用在我的项目里,因为自标注数据集确实存在很多不能分清楚的情况。
训练数据是怎么制作成3:1:1:2的分布的?
采用了一个data collection的过程,从多个数据集中随机选取了样本,具体暂不深究。
生成图片金字塔的参数影响?
resize_factor设置大了,推理时间演唱;小了,容易漏掉一些中小型人脸。
参考
- Zhang, Kaipeng, et al. "Joint face detection and alignment using multitask cascaded convolutional networks." IEEE Signal Processing Letters 23.10 (2016): 1499-1503.
- MTCNN深度解读 代码理解,不含论文解读。
- 人脸检测-MTCNN算法笔记和代码解读 最大池化的kernel size错了,很奇怪,另外全文基本是翻译论文。不推荐。
- 人脸检测--MTCNN从头到尾的详解 很详细,用于巩固细节,推荐。
- mtcnn-pytorch 代码解析参考。
这里还有个问题,论文没有给出这个转换的图示,32层是怎么分别转换为2/4/10层的,是不是各自应用了2/4/10通道的1×1的卷积核?这一点需要看代码确定。代码表示是这样的,feature map分别通过不同的卷积层产生多个特征图输出。引用3代码按照论文一样的来,分别使用了三个2/4/10通道的卷积层;作者代码/facenet代码/mtcnn-pytorch代码一样,都采用2/4的卷积层(没包括10的,然后输出两个特征图。