This post involves the summaries of papers addressing hand detection or segmentations.
Left/Right Hand Segmentation
Betancourt, Alejandro, et al. "Left/right hand segmentation in egocentric videos." Computer Vision and Image Understanding 154 (2017): 73-81.
传统的第一人称视角的方法将手部分割看作背景-前景问题,忽略了两点:一是手不仅仅是移动的皮肤,而且有交互性;二是靠得太近的手容易造成遮挡,从而识别为单个分割。这篇论文设计了左右手识别,是基于角度和位置的Maxwell分布的。
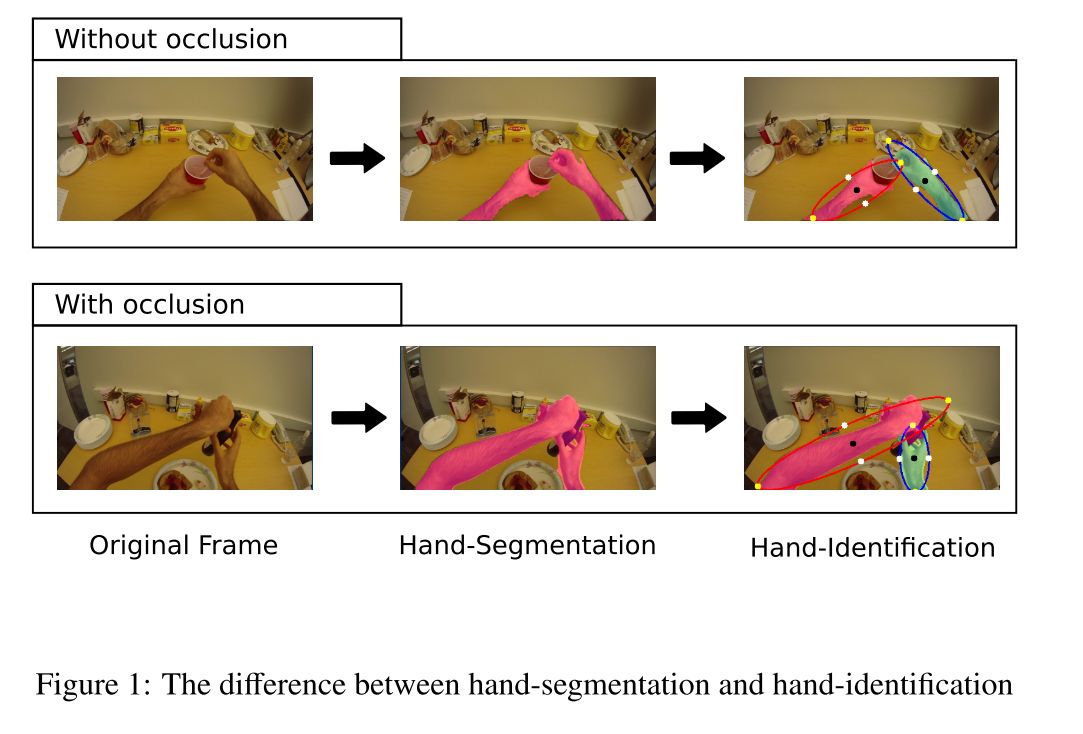
SOTA方法的分析
做手部的分割,SOTA算法一般分为以下几步:
Hand-detection. 这一步的目的是优化用于计算的来源,即从整张图片到包含手的小框,也可以减小后一步中假阳性的概率。检测的算法有很多,作者没有详细讲。
Hand-segmentation. 目的是找到属于第一人称用户的手的像素集合。最古老经典的方法是color-based,作者给出了基于颜色的进阶方法,比如Random Forest classifier[1],训练之后可以区分阳/阴性的像素(阳/阴性是针对是否属于手来说的);除此外还有这个策略的改进版:使用形状敏感分类器或者超像素。
- 焦点和相机位置会破坏皮肤色块的对称性;
- 用户在视野边缘操作物品;
- 两只手靠得很近成为一个色块。
然后有分类讨论法,将图片分为单左手,单右手,两只不同手和两只互动手,但是这种方法把问题看得太简单了。另外的有基于目标相对位置的方法,Bayesian method等。
Hand identification细节
Hand Detection Using Multiple Proposals
Mittal, Arpit, Andrew Zisserman, and Philip HS Torr. "Hand detection using multiple proposals." BMVC. Vol. 40. No. 12. 2011.
Abstract
We describe a two-stage method for detecting hands and their orientation in unconstrained images. The first stage uses three complementary detectors to propose hand bounding boxes. Each bounding box is then scored by the three detectors independently, and a second stage classifier learnt to compute a final confidence score for the proposals using these features.
We make the following contributions: (i) we add context-based and skin-based proposals to a sliding window shape based detector to increase recall; (ii) we develop a new method of non-maximum suppression based on super-pixels; and (iii) we introduce a fully annotated hand dataset for training and testing.
We show that the hand detector exceeds the state of the art on two public datasets, including the PASCAL VOC 2010 human layout challenge.
Aim
This paper aims to propose a robust and reliable hand detector that can address many challenging issues or risks in human visual recognition. The challenges include detecting human hands that are varied in shape and viewpoint, closed or open, partially occluded, or have different articulations of the fingers, or are holding other objects, etc.
Summary
In general, this paper made two contributions in hand detection domain.
- The proposing of a two-stage hand detector.
- A large dataset of images with ground truth annotations for hands.
Propose hand hypotheses
Firstly, three detectors are used to propose hand hypotheses as bounding boxes separately.
Hand shape detector made use of the hand shape, i.e. a hand consists of the palm and the fingers. The shape detector adopts HOG-based deformable parts model (DPM), and it is actually mixing three components, each of which is an aspect of a hand. The first two filters are both representing the frontal pose and third one demonstrates the profile. See the image below. While training, the algorithm rotates the training images to make the borders of the hand aligned to the axes. The image rotates at a stride of $10^\circ$. The bounding boxes of hands are given and kept through a thresholding and scoring function to keep high recall (90%).

Context detector is based on the assumption that the end of the arms are, in some occasions, more easily to be recognised than the hands. The existence of the ends of arms may provide significant cues for hand detection. The algorithm trains a part based deformable model from the hand bounding box training annotations to capture the features of the context as an extension of hands. The detector is also a mixture of three components just as the shape detector. Notably, the detector does not model the arm explicitly or even the adjacent body parts, but only the area surrounding the hand discriminatively, which reduces the risk of hand occlusion. Similarly, hand proposals are also given by shrinking context boxes.
Skin-based detector is based on the view that skin colours are often distinctive from the colours of other objects in the image. The skin-based detection has two steps: 1) Adopt a global skin detector to detect skin regions. Face colourd can strengthen the ability of the detector, with a reduced risk of unusual lighting or colour balances. Then a simple dual thresholding classifier determines the skin pixels. A recursive process is adopted to update skin regions by considering neighbour pixels above the low threshold as skin components. 2) Adopt Hough transform to fit lines to skin regions or draw the medial line of blob regions. Hands are hypothesised as the ends of the regions.
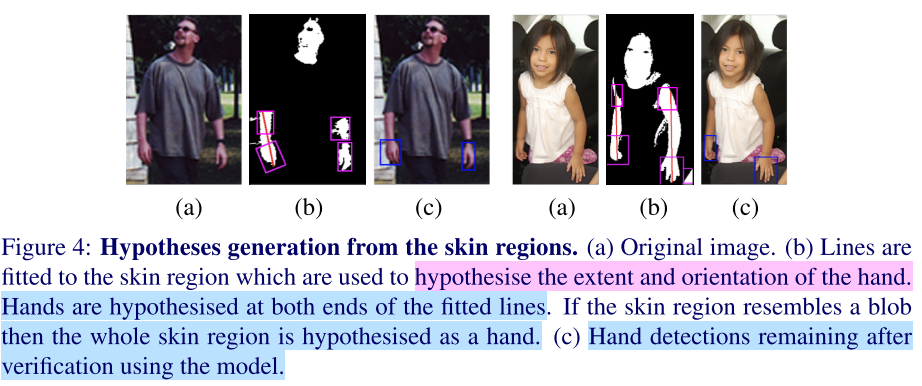
Score the proposals
This step will take the union of the hypotheses generated by all three methods. A discriminatively trained classifier then evaluates the bounding boxes and generate three scores for every bounding box: hand detector score, context detector score and skin detector score. Three scores are combined into a single feature vector. The final linear SVM classifier is learned from the vector and generates the confidence scores for every bounding box. Finally, super-pixel based NMS is adopted to keep the best bounding boxes of the hands. By the way, super-pixel based NMS is adopts NMS on super-pixels instead of the global region to reduce missing bounding boxes.
The paper also introduces an excellent hand dataset. To be brief, the paper presents the structure of the dataset and the evaluation measure.
Experiments are implemented on three datasets: the Hand dataset proposed by the authors, signer dataset and PASCAL VOC 2010 person layout test set. They trained the model on the hand training dataset and determined the parameters on the hand validation dataset. Tests were implemented on all three datasets.
Comments
My thoughts
I would recommend this paper to those who would like to do deep into traditional object detection. Before the fashion of deep learning (AlexNet) in 2012, the model in this paper held the last champions in PASCAL VOC Challenges for human layout detection in hand class in 2010 and 2011. Therefore, I think it might be the peak of traditional hand detection but I need to read more paper to verify my thinking.
However, I may argue that the paper reveals the bottleneck in the development of conventional computer vision based approaches. Firstly, it is still an ensemble of many models or variants of state-of-the-art methods. No novel feature extractor is proposed in the paper. Secondly, the model may hold back in egocentric videos as that there are often no faces.
Comparison
Comparisons are firstly presented between models (Hand & hand and context & hand, context and skin) and results show the competence of the multiple proposal model. On signer dataset, the model in the paper outperforms other models in top 3 or 4 accuracy. On PASCAL VOC 2011 hand detection task, the model increase the AP by over twice the results in 2010.
Applications
The model is highly computationally expensive and it takes 2 minutes for a $360\times630$ image. So the model is not suitable for real-time hand detection. So the extension of the paper should pay attention to speeding up the first stage.