本文描述在反向传播的基础上,一些可以用来提升BP实现,改进网络学习方式的技术。包括:交叉熵代价函数,规范化方法,权重初始化方法和选择好的超参数的一些想法。代码:Star
交叉熵代价函数
对于一般性的二次代价函数:$C=\frac{(y-a)^2}{2}$,其中a是神经元的输出,x和y是训练样本。对于一个常规的神经元来说:

有$z=wx+b, a=\sigma(z)$,那么按照上一讲反向传播,代价函数对于权重和偏置的偏导数分别为:
$$
\frac{\partial C}{\partial w}=(a-y)\sigma'(z)x\\
\frac{\partial C}{\partial b}=(a-y)\sigma'(z)
$$
显然,当神经元的输出z接近1的时候,倒数$\sigma'(z)$会变得很小,那么代价函数的梯度也会很小,此时学习会非常缓慢。回归问题没有将输出限定在一个范围内,而逻辑分类问题常常限定输出到[0, 1]之间,MSE很容易导致学习缓慢。按照人的经验,我们通常是犯错的时候学习的速度更快,为了让神经网络也能够避免代价函数较大的时候学习还很慢的情况,我们引入交叉熵代价函数。
交叉熵推导
在信息论中,已经了解到对于一个离散型随机变量$X$,其取值集合为$\chi$,概率分布函数为$p(x)=Pr(X=x),x\in\chi$。那么事件$X=x_0$的信息量如下:当概率越大,信息量越小。
$$
I(x_0)=-log(p(x_0))
$$
那么对于具有多种可能性的事件来说,我们可以算出每一种可能性的信息量,所有信息量的期望用熵表示:
$$
H(X)=-\sum^n_{i=1}p(x_i)log(p(x_i))
$$
对与0-1分布,或者二分类问题,熵简化为:
$$
H(X)=-p(x)log(p(x))-(1-p(x))log(1-p(x))
$$
重点来了❗。如果对于同一个随机变量X有两个单独的概率分布P(X和Q(X),我们可以用相对熵或者KL散度(Kullback-Leibler divergence)来衡量两个分布的差异。简单点:如果不用Q来描述目标问题,而是用P来描述目标问题,能得到多少信息增量。在机器学习中,P往往表示样本真实分布,而Q就是预测的分布,比如二分类问题的真实分布是[1, 0],而预测分数分别为[0.7, 0.3]。经过反复训练后,Q接近或等于P了,就不会有什么信息增量了,预测结果很完美了。KL散度:
$$
\begin{aligned}
D_{KL}(p||q)&=\sum^n_{i-1}p(x_i)log(\frac{p(x_i)}{q(x_i)})\\
&=\sum^n_{i-1}p(x_i)log(p(x_i))-\sum^n_{i-1}p(x_i)log(q(x_i))\\
&=-H(p(x))+\left[-\sum^n_{i-1}p(x_i)log(q(x_i))\right]
\end{aligned}
$$
观察到前一项就是P分布的熵,后一部分就是交叉熵。机器学习中,真实标签的分布的熵不变,只需要关注交叉熵。学习训练的过程,是KL散度减小的过程,也就是要交叉熵减小的过程。
把一个函数能看做代价函数有两点原因:一是函数值非负,二是如果对于所有训练输入的实际输出接近真实值,那么函数值将接近0。交叉熵显然满足。
交叉熵的定义
对于单个神经元的交叉熵代价函数:
$$
C=-\frac{1}{n}\sum_x[y\text{ln}a+(1-y)\text{ln}(1-a)]
$$
应用链式法则:
$$
\begin{aligned}
\frac{\partial C}{\partial w_j}&=\frac{\partial C}{\partial a}\cdot\frac{\partial a}{\partial z}\cdot\frac{\partial z}{\partial w_j}\\
&=-\frac{1}{n}\sum_x\left(\frac{y}{ \sigma(z)}-\frac{ 1-y}{1-\sigma(z)}\right)\sigma'(z)x_j\\
&=\cdots\text{(some steps)}\\
&=\frac{1}{n}\sum_xx_j(\sigma(z)-y)
\end{aligned}
$$
类似地,计算出关于偏置b的偏导数:
$$
\frac{\partial C}{\partial b}=\frac{1}{n}\sum_x(\sigma(z)-y)
$$
回忆起之前说过的,在使用MSE时,即使误差较大也可能梯度很小。这里就不一样了,激活值和真实值偏差越大,梯度就越大,学习速度越快,是我们需要的。
对于有很多神经元的多层神经网络: $$ C=-\frac{1}{n}\sum_x\sum_j[y_j\text{ln}a_j^L+(1-y_j)\text{ln}(1-a_j^L)] $$ 思考:在多层神经网络中,使用什么代价函数主要看什么?
主要看最后一层神经元是否都是线性神经元。因为线性神经元不会引入$\sigma'(z)$项,也就不会存在明明误差较大学习还很缓慢的情况了。如果都是非线性激活的神经元,交叉熵就比二次代价函数有优势。
思考:在实现反向传播时,交叉熵代价函数带来了什么不同?
只有最后一层的偏导数的公式不同,相较于二次代价函数少了sigma_prime,即$\sigma'(z)$。其他的公式都一样,层与层之间反向传播以及参数的更新都不受影响。
思考:在代码里把二次代价的梯度计算换成交叉熵代价的梯度计算时需要注意什么?
注意把$\sigma'(z^{l-1})$的代码去掉。
交叉熵用于MNIST任务
上次使用二次代价函数时,我用全矩阵mini-batch SGD方法实现了网络结构为[784,30,10],迭代期30,小批量数据大小为10,学习率为1.8时的MNIST数字识别任务,实现的效果见链接。
那么这次我们用0.3的学习效率,其他超参数不变再实现使用全矩阵mini-batch SGD方法。效果:
为什么使用$\eta=0.3$?

Training completed in 85 seconds
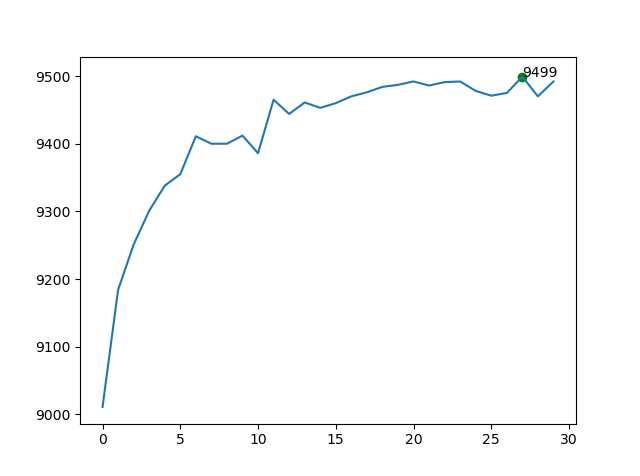 ◎ 使用交叉熵代价函数的网络训练过程
◎ 使用交叉熵代价函数的网络训练过程时间上真的差不太多,计算量是差不多的。准确率的话,从94.87%到94.99%,提升较小,但至少巩固了交叉熵优于二次代价的推断。
交叉熵的含义
教材逆向思考,从需要的代价函数的特点出发,(1)不包含$\sigma'(z)$函数;(2)与误差直接相关,想到了直接在二次代价的偏导数基础上直接去掉$\sigma'(z)$的条件,再利用链式法则,作者得到代价对于激活值的偏导,进而进行积分得到代价函数的形式。也就是这一节开始讲交叉熵推导的终点。这种思考挺有意思,体现的是双向的思考方式。
思考:计算对于权重偏导时,为何不可以通过改变代价函数来消除$x_j$项的影响?
我猜:学习过程本来就需要训练数据,消除了输入神经网络怎么学呢。
柔性最大值
首先,要知道softmax是另一种解决学习缓慢的方法,它的想法是为神经网络定义一种新式的输出层。开始和S型层一样,计算带权输入,但是不用S型函数激活,而是柔性最大值(softmax)函数: $$ a_j^L=\frac{e^{z_j^L}}{\sum_ke^{z_k^L}}\text{ , k=1,2,...,$n^L$} $$ 柔性最大值层的输出可以被看作是一个概率分布,每一个输出的总和为1。
现在我们再来定义柔性最大值函数对应的代价函数,这里指的是关联一个训练输入x的代价函数:对数似然(log-likelihood)代价函数,或者说叫做交叉熵损失[1]
$$ C\equiv-\text{ln}a_y^L $$
可能陷入怀疑,交叉熵损失不应该是这样的吗?$C=-\sum_ky_k^L\text{log}a_k^L$。在这里我们假设真实分布就是所有概率都分布在在正确的类别上,即假设输入属于第i类,则$y_i^L=1,y^L_j=0(j\neq i)$,所有不与i对应的项都是0,求和只剩下第i项$-y^L_i\text{log}a^L_i=-{log}a^L_i$。所以这个交叉熵函数本质上和前文讲过的一样,只不过真实分布是假设的理想情况,而预测分布则是softmax函数的输出$a^L_k$。softmax回归试图将预测分布向假设的真实分布靠近。
这里的y表示训练输入对应的目标输出(当成一个序号),如输入为7的图像,那么对应的对数似然代价是$-lna_7^L$。当网络预测很准时,预测值$a_7^L$就很接近1,对数似然代价就很小;当预测不准时,预测值会很小,代价随之变大。
softmax的性质
柔性最大值的单调性。即证明$\partial a_j^L/\partial z_k^L$在k=j时为正,k≠j时为负: $$ \frac{\partial a_j^L}{\partial z_j^L}=\frac{e^{z_j^L}(\sum_ke^{z_k^L}-e^{z_j^L})}{(\sum_ke^{z_k^L})^2} =a_j^L(1-a_j^L)>0 $$
$$ \frac{\partial a_j^L}{\partial z_i^L}=-a_j^La_i^L<0 $$
柔性最大值的非局部性。很显然,任何特定的激活值都依赖所有的带权输入$z_k^L$。
逆转柔性最大值。柔性最大值函数等号两边同时取对数,得到带权输入的公式:
$$
\text{ln}a_j^L=z_j^L-\underset{\text{constant}}{\text{ln}\sum_ke^{z_k^L}}\\
z_j^L=\text{ln}a_j^L+C
$$
柔性最大值名称的含义。假设softmax变形为:
$$
a_j^L=\frac{e^{cz_j^L}}{\sum_ke^{cz_k^L}}
$$
c=1对应标准softmax,当$c\rightarrow \infty$时输出激活值的极限值是多少?
$$
a_j^L=\frac{1}{\sum_ke^{c(z_k^L-z_j^L)}}
$$
当$z_j^L=argmax{z_k^L}$,只有$c(z_j^L-z_j^L)=0$,其他项都是$\rightarrow -\infty$,那么只有一项是$e^0=1$,其他项趋近0,则极限值为1;当$z_j^L\neq argmax{z_k^L}$,至少有一项次数是正无穷大,那么分母无穷大,极限值为0。这就说明c要是越大,softmax函数就越不理智,只要某个带权输入最大,就判定它激活值大得多,将其定为1,是一种理智的做法,让其他较小的带权输入也能够拥有更大一些的激活函数,原本的输出分布变得柔和了,野百合也有春天。
softmax的反向传播
咱们有了代价函数:$C=-\text{ln}a_y^L$,其中$a_j^L=\frac{e^{z_j^L}}{\sum_ke^{z_k^L}}$,应用我最喜欢的链式法则,先计算对于偏置,输出层的梯度:
$$
\begin{aligned}
\frac{\partial C}{\partial b_j^L}&=
\frac{\partial C}{\partial a_j^L}\cdot
\frac{\partial a_j^L}{\partial z_j^L}\cdot
\frac{\partial z_j^L}{\partial b_j^L}\\
&=-\frac{1}{a_j^L}\cdot
a_j^L(1-a_j^L)\cdot1\\
&=a_j^L-y_j\text{ , where $y_j=1$.}
\end{aligned}
$$
同理,对于权重:$\partial C/\partial w_j^L=a_k^{L-1}(a_j^L-y_j)$。
❗注意:真实应用的时候,一定要考虑假设真实分布$y_j^L=1$,其他为0,所以这里代价函数C实际上是$C_j$。softmax传播梯度时,给“真实值”关联的梯度才会减1,其他的是保留softmax函数值。以下是简短证明: $$ \frac{\partial C_j}{\partial b_i^L}=-\frac{1}{a_j^L}\cdot(-a_j^La_i^L)=a_i^L $$ 我们还可以发现,对数似然代价函数计算出的梯度和之前的交叉熵代价的梯度几乎一样,说明具有对数似然代价的softmax层可以看作是具有交叉熵代价的S型输出层。
例子:加入带权输入$z_j^L$为[1, 2, 5, 2],计算softmax输出为[0.02, 0.04, 0.89, 0.04]。假设输入x为3,真实分布应该为[0, 0, 1, 0],梯度就应该是[0.02, 0.04, 0.89-1, 0.04]=[0.02, 0.04, -0.11, 0.04]。
过度拟合和规范化
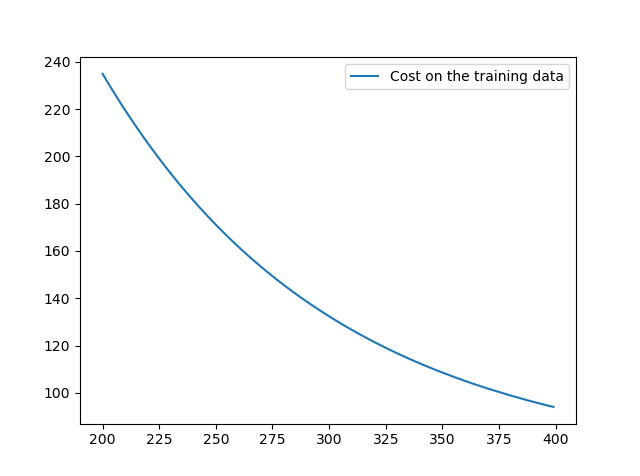
还是围绕MNIST手写数字的识别任务,这一次我们只使用前1000幅图像。有限的训练数据会让泛化问题更凸显。设置交叉熵代价,学习速率为0.5,小批量数据大小为10,训练400个迭代期,训练结果只画出200-399迭代期的变化。
| |
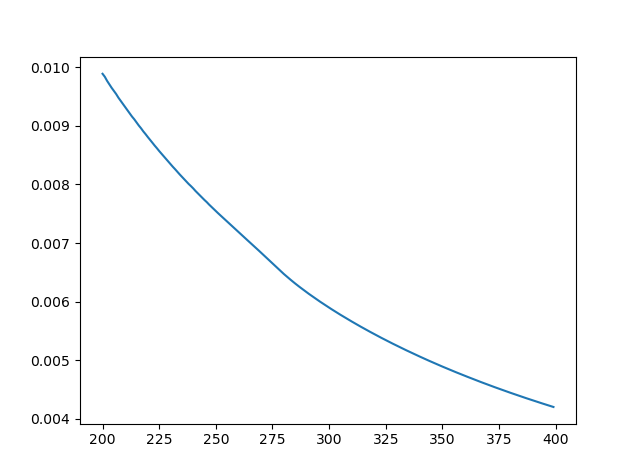 ◎ 训练集的代价变化
◎ 训练集的代价变化
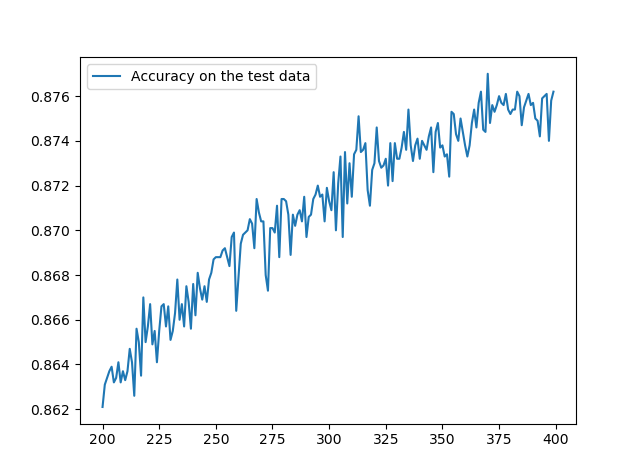
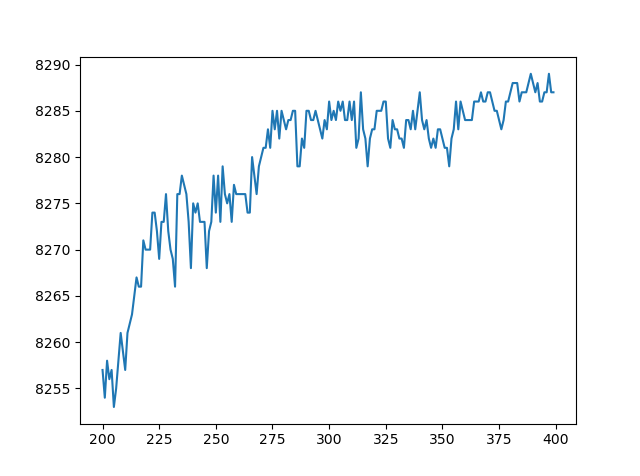 ◎ 测试集的准确率变化
◎ 测试集的准确率变化代价一直在降低,但是测试准确率在第275迭代期左右就停止了增长,上下波动,所以模型表现的提升只是一种假象。这个网络在第275迭代期后就不能推广到测试数据上,之后的学习都是无用的,已经..过度拟合/过度训练..(overfitting/overtraining)了。
也可以使用测试集的代价变化展示过度拟合现象。
目前有两种方法可以防止泛化:
Early stopping. 使用基于
training_data,validation_data,test_data的Hold-Out方法,在开始过度拟合时停止训练;增加训练样本。有了更多的训练数据,就算是一个规模非常大的网络也不容易过度拟合,或者相比于受限的训练集,过度拟合降低很多了。
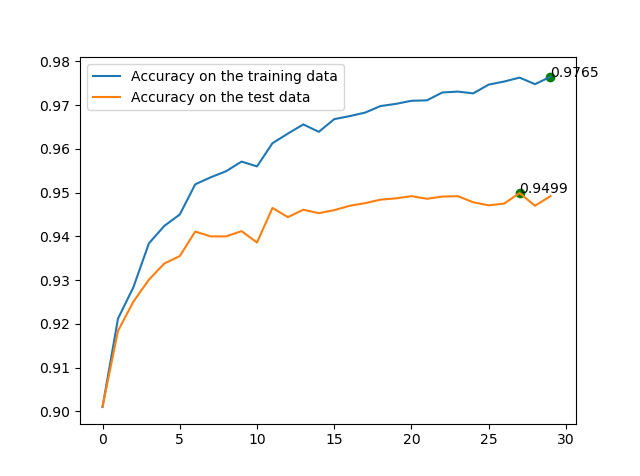 ◎ 50000 training data, 30 epochs, max=0.9499
◎ 50000 training data, 30 epochs, max=0.9499
规范化
L2规范化或者权重衰减:
$$
C=-\frac{1}{n}\sum_{xj}\left[y_j\text{ln}a_j^L+(1-y_j)\text{ln}(1-a_j^L)\right]+\frac{\lambda}{2n}\sum_ww^2
$$
其中$\lambda$为规范化参数。规范化的知识了解很多了,这里看数学上怎么让权重衰减的。加上了规范化项之后,代价对于偏置的偏导数不变,但是对于权重的偏导数变为:
$$
\frac{\partial C}{\partial w}=\frac{\partial C_0}{\partial w}+\frac{\lambda}{n}w
$$
权重的学习规则:
$$
\begin{aligned}
w&\leftarrow w-\eta\frac{\partial C_0}{\partial w}-\eta\frac{\lambda}{n}w\\
&=(1-\eta\frac{\lambda}{n})w-\eta\frac{\partial C_0}{\partial w}
\end{aligned}
$$
因子$(1-\eta\frac{\lambda}{n})$导致了权重的衰减。对于mini-batch SGD,规范化学习规则是:
$$
w\leftarrow (1-\eta\frac{\lambda}{n})w-\frac{\eta}{m}\sum_x\frac{\partial C_x}{\partial w}
$$
$$ b\leftarrow b-\frac{\eta}{m}\sum_x\frac{\partial C_x}{\partial b} $$
现在来跑一下代码,定义$\lambda=0.1$,网络结构不变为[784, 30, 10],小批量数据大小为10,学习效率为0.5,使用交叉熵代价,训练前1000的训练集:
| |
 ◎ 规范化后训练集的代价变化
◎ 规范化后训练集的代价变化
 ◎ 规范化后测试机的准确率变化
◎ 规范化后测试机的准确率变化
结果说明,使用规范化之后,测试集上的准确率在整个迭代期内持续增加,而且最高处比之前的0.82多也要高很多。现在再来测试50000的训练集,为了保证衰减因子相同,规范化系数也要乘以50得到5.0,和之前一样训练30个迭代期,得到下图。可以看出测试集上的准确率从0.9499提升到了0.9629!
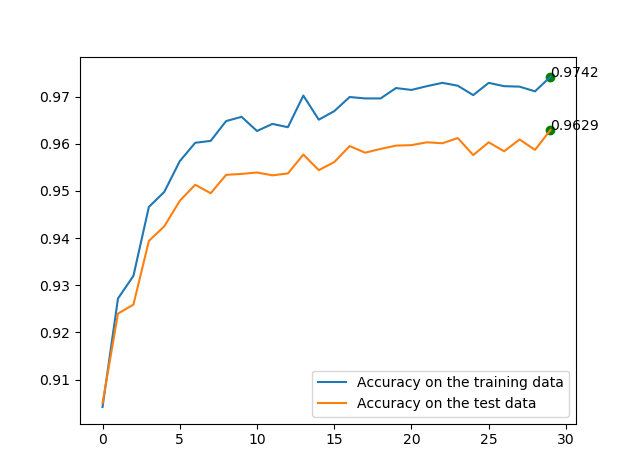 ◎ 50000 training data, 30 epochs, max=0.9499, lambda=5.0
◎ 50000 training data, 30 epochs, max=0.9499, lambda=5.0我们可以进一步修改其他超参数得到更好的效果,这里省略。实践表明,使用不同的随机种子进行多次训练时,没有做规范化的会困在局部最优,每次训练都会给出相差很大的结果,而规范化能够让结果容易复现。这是因为当代价函数无规范化时,权重向量的长度可能会增大到很大,梯度下降仅仅会带来微笑的变化,很难走出困境。
其他技术
L1规范化:这个⽅法是在未规范化的代价函数上加上⼀个权重绝对值的和: $$ C=C_0+\frac{\lambda}{n}\sum_w|w| $$ 得到代价函数的偏导数:($\text{sgn}(w)$表示w的正负性,w为正时为1,为负时为-1) $$ \frac{\partial C}{\partial w}=\frac{\partial C_0}{\partial w}+\frac{\lambda}{n}\text{sgn}(w) $$ 那么L1规范化的网络进行更新的规则是: $$ w\leftarrow w-\frac{\eta\lambda}{n}\text{sgn}(w)-\eta\frac{\partial C_0}{\partial w} $$ 对比L2规范化,我们发现两种规范化的效果都是缩小权重,但是方式不一样。L2规范化中,权重是通过一个和w成比例的量进行缩小的,而L1规范化中是每次向0的方向缩小一个常量。
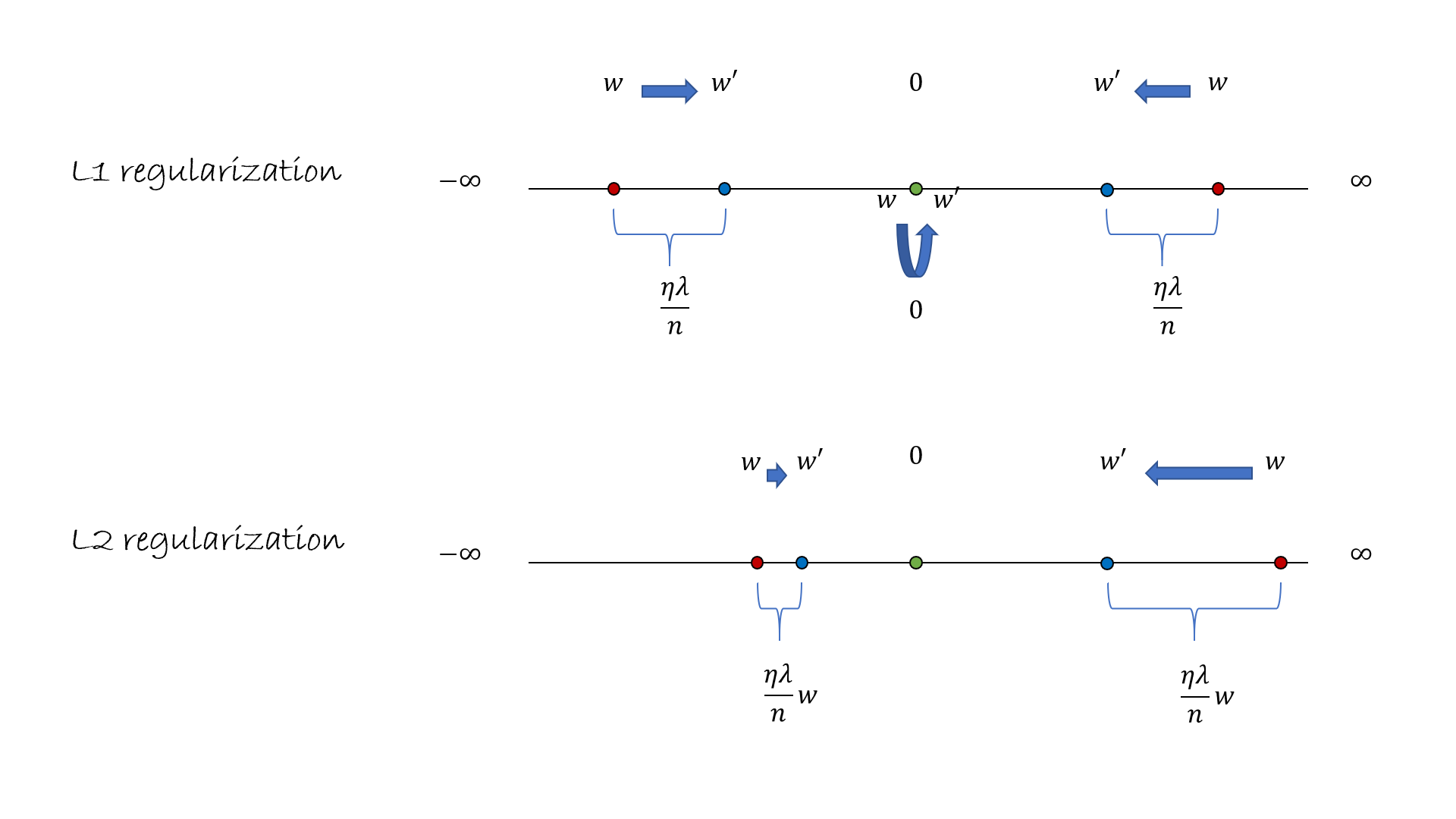 ◎ 不同的规定化:从w到w'的方式不同
◎ 不同的规定化:从w到w'的方式不同弃权(dropout):在每一次输入进行前向传播时,临时地随机地删除掉网络中一半(通常)的隐藏神经元,保持输入层和输出层地神经元不变。后向传播梯度也是通过修改之后的网络。
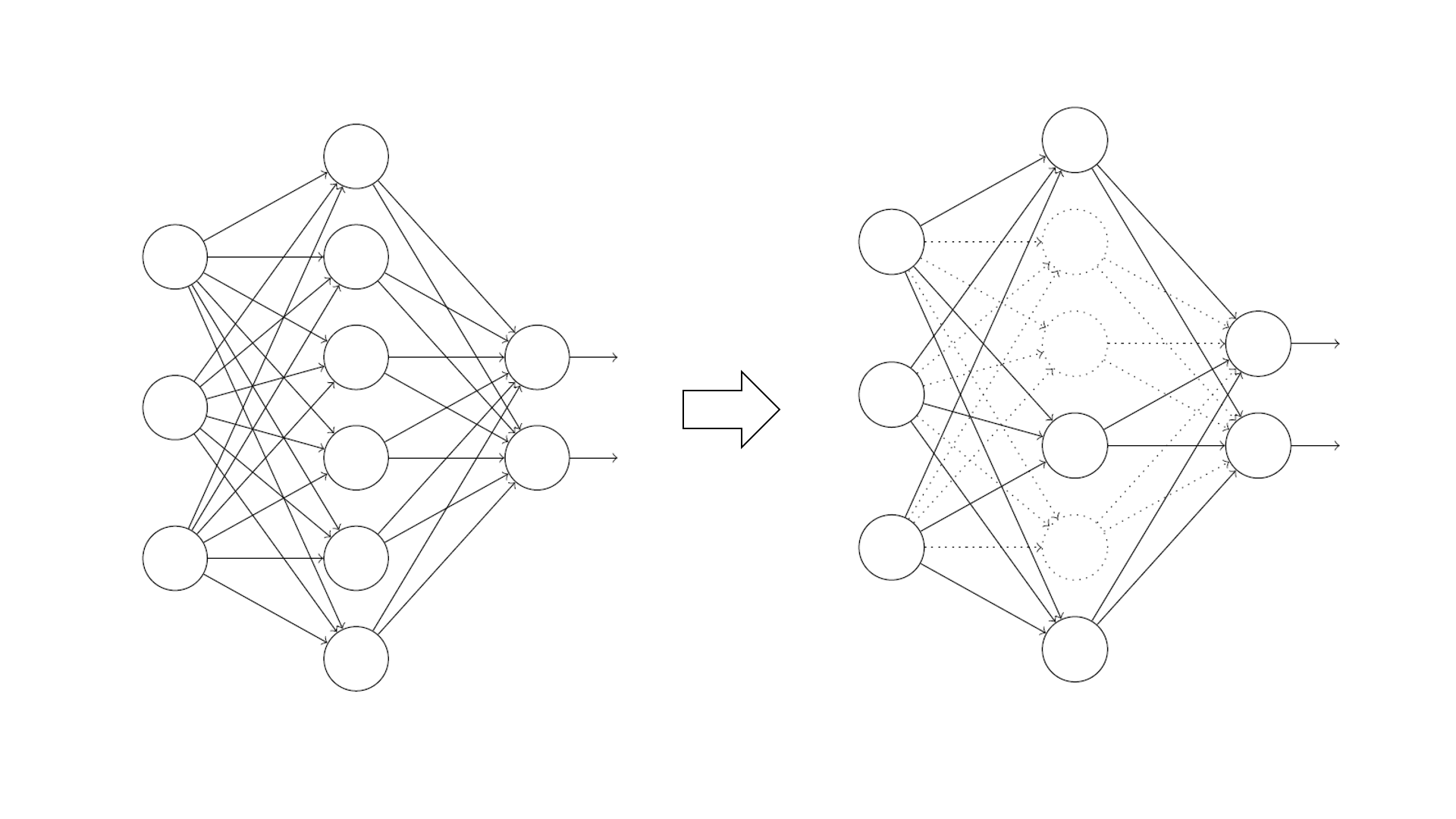 ◎ 部分隐藏神经元临时被弃权
◎ 部分隐藏神经元临时被弃权在一个小批量数据进行过这样的前向和后向传播后,对网络参数进行更新。然后重复这个过程:首先重置弃权的神经元,然后选择一个新的一半随机的隐藏神经元进行删除,对下一个小批量数据计算梯度,更新参数。
⼈为扩展训练数据:当使用更多的训练数据时,分类准确率可以提高,比如我们本来有50000个训练样本,我们使用以下不同大小的训练集,按照“控制变量法”尽量使不同训练集下条件相同,每一个训练集训练完之后使用验证集验证准确率:
[100, 200, 500, 1000, 2000, 5000, 10000, 20000, 50000]
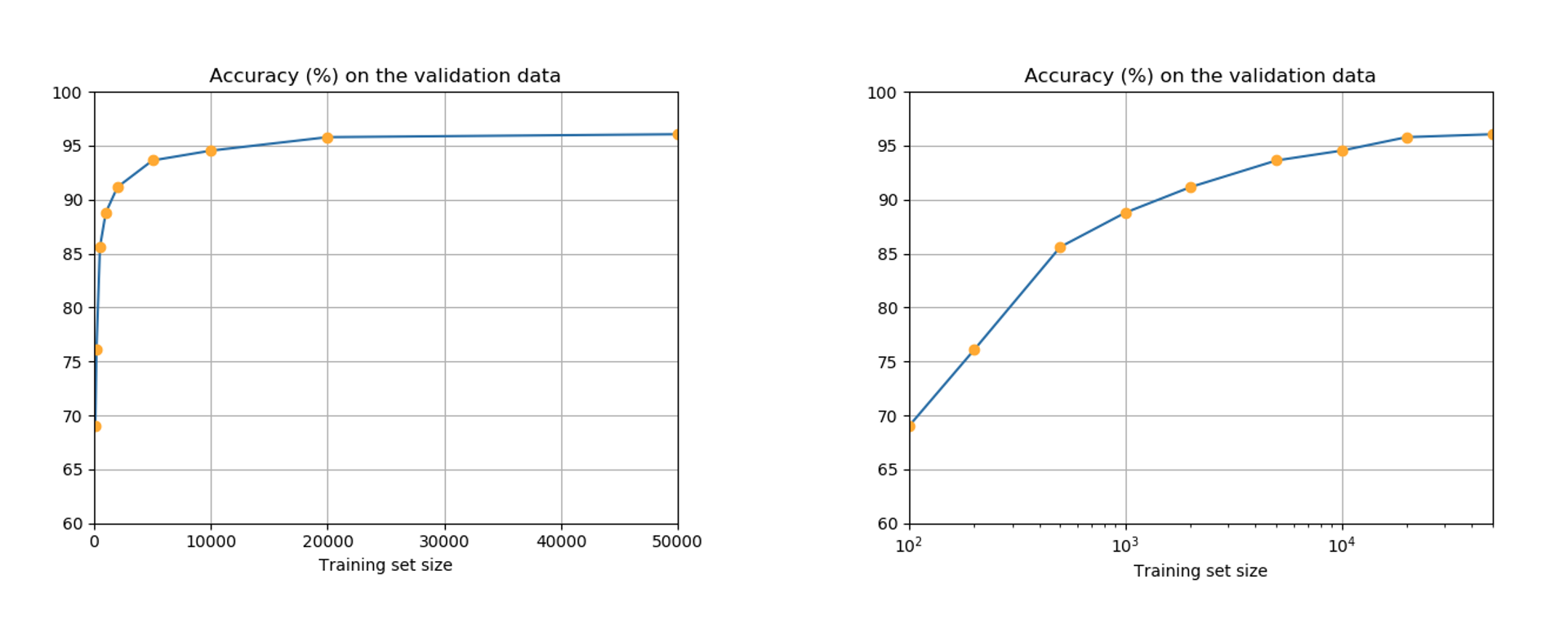 ◎ 随着训练集增加,准确率提高
◎ 随着训练集增加,准确率提高但是这种方法代价很大,在实践中往往做不到。我们可以人为扩展训练数据,如将图片小幅度旋转,扭曲等。这样做的想法就是尽量去模拟真实世界中的变化。这个技术也不总是有用,有时往训练数据里加噪声不如先对数据去噪。
问题:如果我们用过大的旋转来扩展训练数据时会发生什么呢?可能导致模型无法学到数字的特征或者错误的特征。
另外我们比较我们的神经网络模型与sklearn的SVM模型,得到如下训练结果。应该注意的是,训练集影响模型的训练结果,所以我们在讨论什么算法更好时,也要说明是在用什么训练条件/训练集。
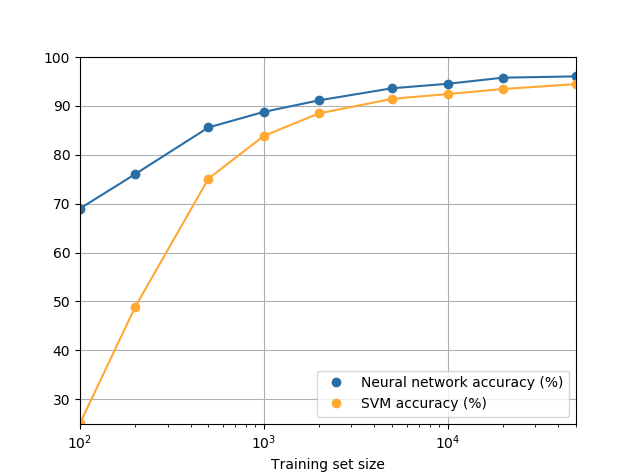 ◎ 同样训练集下神经网络表现始终优于SVM
◎ 同样训练集下神经网络表现始终优于SVM权重初始化
之前的初始化是根据归一化的高斯随机变量来选择权重和偏置的,(各自)均值为0,标准差为1。但是在某些情况下,如假设训练输入神经元一半为1,一半为0,对于1000个输入神经元的网络来说,带权输入就是501个归一化高斯随机变量的和,这个带权输入的标准差为$\sqrt{501}\approx 22.4$,高斯分布非常宽,带权输入z的绝对值很容易为大值,此时$\sigma'(z)$很小,神经元饱和,学习缓慢。
所以需要把z的高斯分布“挤压”一下。对于有$n_{in}$个输入神经元的神经网络,偏置的高斯分布仍为归一化的高斯分布,但是权重的分布的均值为0,标准差很小,为$\text{SD}=\frac{1}{\sqrt{n_{in}}}$。对于高斯分布$N(\mu,\sigma^2)$,从标准的高斯分布转换的关系为:sigma * np.random.randn(...) + mu。
那么对于同样条件($n_{in}=1000$,500个输入为1,另外为0)的神经网络来说,输入层的带权输入z由500项权重加1项偏置组成,则总标准差为:
$$
\text{SD}_z=\sqrt{\left(\sqrt{\frac{1}{1000}}\right)^2\times 500 +1}=\sqrt{\frac{3}{2}}=1.22
$$
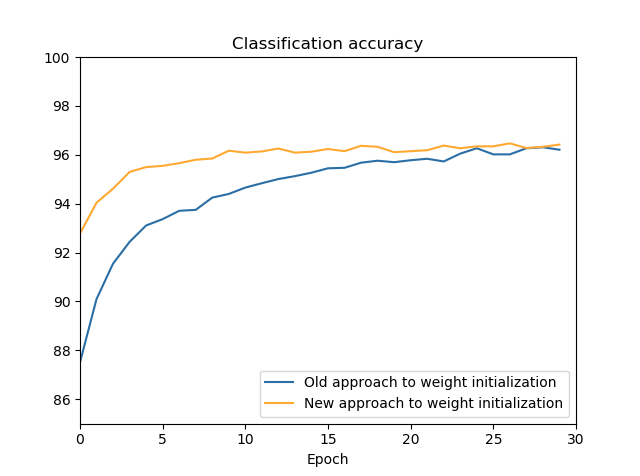 ◎ 新的初始化方式显然更快
◎ 新的初始化方式显然更快
问题:待解

如何选择神经网络的超参数
- 宽泛策略。简化参数构成,逐个调整每个超参数,由简单到复杂,慢慢提升性能。原则:前期应从实验中尽早得到反馈
- 学习速率。主要是大了不容易收敛,小了学习很慢,所以选择在训练数据的代价立即开始下降而非震荡或者增加时作为$\eta$的阈值的估计,不需要太精确。然后尝试更大的值,直到找到一个$\eta$值使得在开始若干回合后代价开始震荡或者增加。相反,要是刚开始就尝试到了令代价震荡或者增加的值,就尝试更低的值。
- 提前停止。用验证准确率说着验证集代价决定。
- 学习速率调整。随着学习的进行,设置可变的学习速率,可能需要大量优化。
- 规范化参数。从不适用规范化开始,确定$\eta$的值。然后使用确定的$\eta$,选择好的$\lambda$。找的时候先找量级。
- 小批量数据大小。运算时间和空间的权衡。
- 自动技术。搜索算法如网格搜索,系统化地对超参数的参数空间的网格进行搜索。
总结
改进超参数的过程就像调节PID控制器,有基本的思路,但有时也需要来回往复进行调整。原则是要细致地监控神经网络地行为,特别是验证集上的准确率。目标应该是发展出一个工作习惯或流程来确保自己可以熟练地优化参数,这样保留足够的时间来尝试对重要参数进行更加细节的优化。
书中还讲到了其他优化代价函数的技术,包括Hessian和momentum技术,比mini-batch SGD有更好的效果,由于近期有更重要的事情,关于其他技术的学习暂时停笔。
另外还细致地讲解了tanh和ReLU神经元,大致是在讲理解功能和应用,同样地,暂时不看了,暂时基本有个了解,以后还会专门开个文章写激活函数的理解。
书的这一节还讲到了一些神经网络技术的历史和思考,是跳出技术原理,在更高层面上的对算法的理解,值得复习。
参考
- Neural Networks and Deep Learning
- 一文搞懂交叉熵在机器学习中的使用,透彻理解交叉熵背后的直觉
- Softmax 函数的特点和作用是什么? - 薰风初入弦的回答 - 知乎 https://www.zhihu.com/question/23765351/answer/793643600
- Softmax 函数的特点和作用是什么? - 忆臻的回答 - 知乎 https://www.zhihu.com/question/23765351/answer/240869755